
hills
Posts
Post Categories / Tags
**AI Safety and Ethics**: This category focuses on the safety and ethical considerations of AI and deep learning, including fairness, transparency, and robustness.
**Attention and Transformer Models**: Techniques that focus on the use of attention mechanisms and transformer models in deep learning.
**Audio and Speech Processing**: Techniques for processing and understanding audio data and speech.
**Federated Learning**: Techniques for training models across many decentralized devices or servers holding local data samples, without exchanging the data samples themselves.
**Few-Shot Learning**: Techniques that aim to make accurate predictions with only a few examples of each class.
**Generative Models**: This includes papers on generative models like Generative Adversarial Networks, Variational Autoencoders, and more.
**Graph Neural Networks**: Techniques for dealing with graph-structured data.
**Image Processing and Computer Vision**: This category includes papers focused on techniques for processing and understanding images, such as convolutional neural networks, object detection, image segmentation, and image generation.
**Interpretability and Explainability**: This category is about techniques to understand and explain the predictions of deep learning models.
**Large Language Models**: These papers focus on large scale models for understanding and generating text, like GPT-3, BERT, and other transformer-based models.
**Meta-Learning**: Techniques that aim to design models that can learn new tasks quickly with minimal amount of data, often by learning the learning process itself.
**Multi-modal Learning**: Techniques for models that process and understand more than one type of input, like image and text.
**Natural Language Processing**: Techniques for understanding and generating human language.
**Neural Architecture Search**: These papers focus on methods for automatically discovering the best network architecture for a given task.
**Optimization and Training Techniques**: This category includes papers focused on how to improve the training process of deep learning models, such as new optimization algorithms, learning rate schedules, or initialization techniques.
**Reinforcement Learning**: Papers in this category focus on using deep learning for reinforcement learning tasks, where an agent learns to make decisions based on rewards it receives from the environment.
**Representation Learning**: These papers focus on learning meaningful and useful representations of data.
**Self-Supervised Learning**: Techniques where models are trained to predict some part of the input data, using this as a form of supervision.
**Time Series Analysis**: Techniques for dealing with data that has a temporal component, like RNNs, LSTMs, and GRUs.
**Transfer Learning and Domain Adaptation**: Papers here focus on how to apply knowledge learned in one context to another context.
**Unsupervised and Semi-Supervised Learning**: Papers in this category focus on techniques for learning from unlabeled data.
go to post
Attention is All You Need
‘Attention is All You Need’ by Vaswani et al., 2017, is a seminal paper in the field of natural language processing (NLP) that introduces the Transformer model, a novel architecture for sequence transduction (or sequence-to-sequence) tasks such as machine translation. It has since become a fundamental building block for many state-of-the-art models in NLP, including BERT, GPT, and others.
Background and Motivation
Before this paper, most sequence transduction models were based on Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs), or a combination of both. These models performed well but had some limitations. For instance, RNNs have difficulties dealing with long-range dependencies due to the vanishing gradient problem. CNNs, while mitigating some of these problems, have a fixed maximum context window and require many layers to increase it. Both architectures have inherently sequential computation which is hard to parallelize, slowing down training.
The Transformer Model
The authors propose the Transformer model, which dispenses with recurrence and instead relies entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for much higher parallelization and can theoretically capture dependencies of any length in the input sequence.
The Transformer follows the general encoder-decoder structure but with multiple self-attention and point-wise, fully connected layers for both the encoder and decoder.
Architecture
The core components of the Transformer are:
Self-Attention (Scaled Dot-Product Attention): This is the fundamental operation that replaces recurrence in the model. Given a sequence of input tokens, for each token, a weighted sum of all tokens' representations is computed, where the weights are determined by the compatibility (or attention) of each token with the token of interest. This compatibility is computed using a dot product between the query and key (both derived from input tokens), followed by a softmax operation to obtain the weights. The weights are then used to compute a weighted sum of values (also derived from input tokens). The scaling factor in the dot-product attention is the square root of the dimension of the key vectors, which is used for stability.
The queries, keys, and values in the Transformer model are derived from the input embeddings.
The input embeddings are the vector representations of the input tokens. These vectors are high-dimensional, real-valued, and dense. They are typically obtained from pre-trained word embedding models like Word2Vec or GloVe, although they can also be learned from scratch.
In the context of the Transformer model, for each token in the input sequence, we create a Query vector (Q), a Key vector (K), and a Value vector (V). These vectors are obtained by applying different learned linear transformations (i.e., matrix multiplication followed by addition of a bias term) to the input embeddings. In other words, we have weight matrices WQ, WK, and WV for the queries, keys, and values, respectively. If we denote the input embedding for a token by x, then:
Q = WQ * x K = WK * x V = WV * x
These learned linear transformations (the weights WQ, WK, and WV) are parameters of the model and are learned during training through backpropagation and gradient descent.
In terms of connections, the Query (Q), Key (K), and Value (V) vectors are used differently in the attention mechanism.
- The Query vector is used to score each word in the input sequence based on its relevance to the word we're focusing on in the current step of the model.
- The Key vectors are used in conjunction with the Query vector to compute these relevance scores.
- The Value vectors provide the actual representations that are aggregated based on these scores to form the output of the attention mechanism.
The scoring is done by taking the dot product of the Query vector with each Key vector, which yields a set of scores that are then normalized via a softmax function. The softmax-normalized scores are then used to take a weighted sum of the Value vectors.
In terms of shape, Q, K, and V typically have the same dimension within a single attention head. However, the model parameters (the weight matrices WQ, WK, and WV) determine the actual dimensions. Specifically, these matrices transform the input embeddings (which have a dimension of d_model in the original 'Attention is All You Need' paper) to the Q, K, and V vectors (which have a dimension of d_k in the paper). In the paper, they use d_model = 512 and d_k = 64, so the transformation reduces the dimensionality of the embeddings.
In the multi-head attention mechanism of the Transformer model, these transformations are applied independently for each head, so the total output dimension of the multi-head attention mechanism is d_model = num_heads * d_k. The outputs of the different heads are concatenated and linearly transformed to match the desired output dimension.
So, while Q, K, and V have the same shape within a single head, the model can learn different transformations for different heads, allowing it to capture different types of relationships in the data.
After the Q (query), K (key), and V (value) matrices are calculated, they are used to compute the attention scores and subsequently the output of the attention mechanism.
Here's a step-by-step breakdown of the process:
Compute dot products: The first step is to compute the dot product of the query with all keys. This is done for each query, for every position in the input sequence. The result is a matrix of shape (t, t), where t is the number of tokens in the sequence.
Scale: The dot product scores are then scaled down by a factor of square root of the dimension of the key vectors (d_k). This is done to prevent the dot product results from growing large in magnitude, leading to tiny gradients and hindering the learning process due to the softmax function used in the next step.
Apply softmax: Next, a softmax function is applied to the scaled scores. This has the effect of making the scores sum up to 1 (making them probabilities). The softmax function also amplifies the differences between the largest and other elements.
Multiply by V: The softmax scores are then used to weight the value vectors. This is done by multiplying the softmax output (which has the same shape as the key-value pairs) with the V (value) matrix. This step essentially takes a weighted sum of the value vectors, where the weights are the attention scores.
Summation: Finally, the results from the previous step for each query are summed together to produce the output of the attention mechanism for that particular query. This output is then used as input to the next layer in the Transformer model.
In the multi-head attention mechanism, the model uses multiple sets of these transformations, allowing it to learn different types of attention (i.e., different ways of weighting the relevance of other tokens when processing a given token) simultaneously. Each set of transformations constitutes an ‘attention head’, and the outputs of all heads are concatenated and linearly transformed to result in the final output of the multi-head attention mechanism.
Multi-Head Attention: Instead of performing a single attention function, the model uses multiple attention functions, called heads. For each of these heads, the model projects the queries, keys, and values to different learned linear projections, then applies the attention function on these projected versions. This allows the model to jointly attend to information from different representation subspaces at different positions.
Position-Wise Feed-Forward Networks: In addition to attention, the model uses a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
Positional Encoding: Since the model doesn't have any recurrence or convolution, positional encodings are added to the input embeddings to give the model some information about the relative or absolute position of the tokens in the sequence. The positional encodings have the same dimension as the embeddings so that they can be summed. A specific function based on sine and cosine functions of different frequencies is used.
Training and Results
The authors trained the Transformer on English-to-German and English-to-French translation tasks. It achieved new state-of-the-art results on both tasks while using less computational resources (measured in training time or FLOPs).
The Transformer's success in these tasks demonstrates its ability to handle long-range dependencies, given that translating a sentence often involves understanding the sentence as a whole.
Implications
Delving Deep into Rectifiers
This paper proposed a new initialization method for the weights in neural networks and introduced a new activation function called Parametric ReLU {PReLU}.
### Introduction
This paper's main contributions are the introduction of a new initialization method for rectifier networks {called "He Initialization"} and the proposal of a new variant of the ReLU activation function called the Parametric Rectified Linear Unit {PReLU}.
### He Initialization
The authors noted that the existing initialization methods, such as Xavier initialization, did not perform well for networks with rectified linear units {ReLUs}. Xavier initialization is based on the assumption that the activations are linear. However, ReLUs are not linear functions, which might cause the variance of the outputs of neurons to be much larger than the variance of their inputs.
To address this issue, the authors proposed a new method for initialization, which they referred to as "He Initialization". It is similar to Xavier initialization, but it takes into account the non-linearity of the ReLU function. The initialization method is defined as follows:
\[
W \sim \mathcal{N}\left(0, \sqrt{\frac{2}{n_{\text{in}}}}\right)
\]
where \(n_{\text{in}}\) is the number of input neurons, \(W\) is the weight matrix, and \(\mathcal{N}(0, \sqrt{\frac{2}{n_{\text{in}}}})\) represents a Gaussian distribution with mean 0 and standard deviation \(\sqrt{\frac{2}{n_{\text{in}}}}\).
### Parametric ReLU {PReLU}
The paper also introduces a new activation function called the Parametric Rectified Linear Unit {PReLU}. The standard ReLU activation function is defined as \(f(x) = \max(0, x)\), which means that it outputs the input directly if it is positive, otherwise, it outputs zero. While it has advantages, the ReLU function also has a drawback known as the "dying ReLU" problem, where a neuron might always output 0, effectively killing the neuron and preventing it from learning during the training process.
The PReLU is defined as follows:
\[
f(x) = \begin{cases}
x & \text{if } x \geq 0 \newline
a_i x & \text{if } x < 0
\end{cases}
\]
where \(a_i\) is a learnable parameter. When \(a_i\) is set to 0, PReLU becomes the standard ReLU function. When \(a_i\) is set to a small value {e.g., 0.01}, PReLU becomes the Leaky ReLU function. However, in PReLU, \(a_i\) is learned during the training process.
### Experimental Results
The authors tested their methods on the ImageNet Large-Scale Visual Recognition Challenge 2014 {ILSVRC2014} dataset and achieved top results. Using an ensemble of their models, they achieved an error rate of 4.94%, surpassing the human-level performance of 5.1%.
### Implications
The introduction of He Initialization and PReLU have had significant impacts on the field of deep learning:
- **He Initialization:** It has become a common practice to use He Initialization for neural networks with ReLU and its variants. This method helps mitigate the problem of vanishing/exploding gradients, enabling the training
of deeper networks.
- **PReLU:** PReLU and its variant, Leaky ReLU, are now widely used in various deep learning architectures. They help mitigate the "dying ReLU" problem, where some neurons essentially become inactive and cease to contribute to the learning process.
### Limitations
While the He initialization and PReLU have been widely adopted, they are not without limitations:
- **He Initialization:** While this method works well with ReLU and its variants, it might not be the best choice for other activation functions. Therefore, the choice of initialization method still depends on the specific activation function used in the network.
- **PReLU:** While PReLU helps mitigate the dying ReLU problem, it introduces additional parameters to be learned, increasing the complexity and computational cost of the model. In some cases, other methods like batch normalization or other activation functions might be preferred due to their lesser computational complexity.
### Conclusion
In conclusion, the paper "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification" made significant contributions to the field of deep learning by introducing He initialization and the PReLU activation function. These methods have been widely adopted and have helped improve the performance of deep neural networks, particularly in computer vision tasks.
go to post
Cyclical Learning Rates for Training Neural Networks
"Cyclical Learning Rates for Training Neural Networks" introduced the concept of cyclical learning rates, a novel method of adjusting the learning rate during training.
### Introduction
Typically, when training a neural network, a constant learning rate or a learning rate with a predetermined schedule {such as step decay or exponential decay} is used. However, these approaches may not always be optimal. A learning rate that is too high can cause training to diverge, while a learning rate that is too low can slow down training or cause the model to get stuck in poor local minima.
In this paper, Leslie N. Smith introduced the concept of cyclical learning rates {CLR}, where the learning rate is varied between a lower bound and an upper bound in a cyclical manner. This approach aims to combine the benefits of both high and low learning rates.
### Cyclical Learning Rates
In the CLR approach, the learning rate is cyclically varied between reasonable boundary values. The learning rate increases linearly or exponentially from a lower bound to an upper bound, and then decreases again. This cycle is repeated for the entire duration of the training process.
Mathematically, the learning rate for a given iteration can be calculated as:
\[
\text{lr}(t) = \text{lr}_{\text{min}} + 0.5 \left( \text{lr}_{\text{max}} - \text{lr}_{\text{min}} \right) \left( 1 + \cos\left( \frac{T_{\text{cur}}}{T} \pi \right) \right)
\]
where:
- \(\text{lr}(t)\) is the learning rate at iteration \(t\),
- \(\text{lr}_{\text{min}}\) and \(\text{lr}_{\text{max}}\) are the minimum and maximum boundary values for the learning rate,
- \(T_{\text{cur}}\) is the current number of iterations since the start of the cycle, and
- \(T\) is the total number of iterations in one cycle.
### Experimental Results
The author tested the CLR method on various datasets and neural network architectures, including CIFAR-10, CIFAR-100, and ImageNet. The results showed that CLR can lead to faster convergence and improved generalization performance compared to traditional learning rate schedules.
### Implications
The concept of cyclical learning rates has significant implications for the field of machine learning:
- **Efficiency:** CLR can potentially save a considerable amount of time during model training, as it can lead to faster convergence.
- **Performance:** CLR can improve the generalization performance of the model, potentially leading to better results on the test set.
- **Hyperparameter Tuning:** CLR reduces the burden of hyperparameter tuning, as it requires less precise initial settings for the learning rate.
### Limitations
While CLR is a powerful tool, it's not without its limitations:
- **Cycle Length:** Determining the appropriate cycle length can be challenging. While the paper provides some guidelines, it ultimately depends on the specific dataset and model architecture.
- **Boundary Values:** Similarly, determining the appropriate boundary values for the learning rate can be non-trivial. The paper suggests using a learning rate range test to find these values.
### Conclusion
In conclusion, "Cyclical Learning Rates for Training Neural Networks" made a significant contribution to the field of machine learning by introducing a novel approach to adjust the learning rate during training. The concept of cyclical learning rates has since been widely adopted and implemented in various deep learning libraries.
go to post
Large Batch Training of Convolutional Networks
## 0. TLDR
**Generally speaking, large mini-batches improve training speed but worsen accuracy / generalization. Idea is to use higher learning rates with larger mini-batches, but use a warmup period for the learning rate during the beginning of training. Seems to do well and speeds up training.**
## 1. Background
Typically, stochastic gradient descent (SGD) and its variants are used to train deep learning models, and these methods make updates to the model parameters based on a mini-batch of data. Smaller mini-batches can result in noisy gradient estimates, which can help avoid local minima, but also slow down convergence. Larger mini-batches can provide a more accurate gradient estimate and allow for higher computational efficiency due to parallelism, but they often lead to poorer generalization performance.
## 2. Problem
The authors focus on the problem of maintaining model performance while increasing the mini-batch size. They aim to leverage the computational benefits of large mini-batches without compromising the final model accuracy.
## 3. Methodology
The authors propose a new learning rate scaling rule for large mini-batch training. The rule is straightforward: when the mini-batch size is multiplied by \(k\), the learning rate should also be multiplied by \(k\). This is in contrast to the conventional wisdom that the learning rate should be independent of the mini-batch size.
However, simply applying this scaling rule at the beginning of training can result in instability or divergence. To mitigate this, the authors propose a warmup strategy where the learning rate is initially small, then increased to its 'scaled' value over a number of epochs.
In mathematical terms, the proposed learning rate schedule is given by:
\[
\eta = \begin{cases}
\frac{\eta_{\text{base}}}{5} \cdot \left(\frac{\text{epoch}}{5}\right) & \text{if epoch} \leq 5 \\
\eta_{\text{base}} \cdot \left(1 - \frac{\text{epoch}}{\text{total epochs}}\right) & \text{if epoch} > 5
\end{cases}
\]
where \(\eta_{\text{base}}\) is the base learning rate.
## 4. Experiments and Results
The authors conducted experiments on ImageNet with a variety of CNN architectures, including AlexNet, VGG, and ResNet. They found that their proposed learning rate scaling rule and warmup strategy allowed them to increase the mini-batch size up to 32,000 without compromising model accuracy.
Moreover, they were able to achieve a training speedup nearly proportional to the increase in mini-batch size. For example, using a mini-batch size of 8192, training AlexNet and ResNet-50 on ImageNet was 6.3x and 5.3x faster, respectively, compared to using a mini-batch size of 256.
## 5. Implications
The paper has significant implications for the training of deep learning models, particularly in scenarios where computational resources are abundant but time is a constraint. By allowing for successful training with large mini-batches, the proposed methods can significantly speed up the training process.
Furthermore, the paper challenges conventional wisdom on the relationship between the learning rate and the mini-batch size, which could stimulate further research into the optimization dynamics of deep learning models.
However, it's worth noting that the proposed methods may not be applicable or beneficial in all scenarios. For example, they
Here is a plot of the learning rate schedule proposed by the authors. The x-axis represents the number of epochs, and the y-axis represents the learning rate.
As you can see, the learning rate is initially small and then increases linearly for the first 5 epochs. After the 5th epoch, the learning rate gradually decreases for the remaining epochs. This is the 'warmup' strategy proposed by the authors.
In the context of this plot, \(\eta_{\text{base}}\) is set to 0.1, and the total number of epochs is 90, which aligns with typical settings for training deep learning models on ImageNet.
This learning rate schedule is one of the key contributions of the paper, and it's a strategy that has since been widely adopted in the training of deep learning models, particularly when using large mini-batches.
Overall, while large-batch training might not always be feasible or beneficial due to memory limitations or the risk of poor generalization, it presents a valuable tool for situations where time efficiency is critical and computational resources are abundant. Furthermore, the insights from this paper about the interplay between batch size and learning rate have broadened our understanding of the optimization dynamics in deep learning.
go to post
A disciplined approach to neural network hyper-parameters: Part 1
## 1. TLDR
**Bag of tricks for optimizing optimization hyperparameters:**
**1. Use a learning rate finder**
**2. When batch_size is multiplied by $k$, learning rate should be multiplied by $\sqrt(k)$**
**3. Use cyclical momentum {LR high --> momentum low and vice versa}**
**4. Use weight decay {first set to 0, then find best LR, then tune weight decay}**
The paper "A disciplined approach to neural network hyper-parameters: Part 1 - learning rate, batch size, momentum, and weight decay" by Leslie N. Smith and Nicholay Topin in 2018 presents a systematic methodology for the selection and tuning of key hyperparameters in training neural networks.
## 1. Background
Training a neural network involves numerous hyperparameters, such as the learning rate, batch size, momentum, and weight decay. These hyperparameters can significantly impact the model's performance, yet their optimal settings are often problem-dependent and can be challenging to determine. Traditionally, these hyperparameters have been tuned somewhat arbitrarily or through computationally expensive grid or random search methods.
## 2. Problem
The authors aim to provide a disciplined, systematic approach to the selection and tuning of these critical hyperparameters. They seek to provide a methodology that reduces the amount of guesswork and computational resources required in hyperparameter tuning.
## 3. Methodology
The authors propose various strategies and techniques for hyperparameter tuning:
**a. Learning Rate:** They recommend the use of a learning rate finder, which involves training the model for a few epochs while letting the learning rate increase linearly or exponentially, and plotting the loss versus the learning rate. The learning rate associated with the steepest decrease in loss is chosen.
**b. Batch Size:** The authors propose a relationship between batch size and learning rate: when the batch size is multiplied by \(k\), the learning rate should also be multiplied by \(\sqrt{k}\).
**c. Momentum:** The authors recommend a cyclical momentum schedule: when the learning rate is high, the momentum should be low, and vice versa.
**d. Weight Decay:** The authors advise to first set the weight decay to 0, find the optimal learning rate, and then to tune the weight decay.
## 4. Experiments and Results
The authors validate their methodology on a variety of datasets and models, including CIFAR-10 and ImageNet. They found that their approach led to competitive or superior performance compared to traditionally tuned models, often with less computational cost.
## 5. Implications
This paper offers a structured and more intuitive way to handle hyperparameter tuning, which can often be a complex and time-consuming part of model training. The methods proposed could potentially save researchers and practitioners a significant amount of time and computational resources.
Moreover, the findings challenge some common practices in deep learning, such as the use of a fixed momentum value. This could lead to more exploration into dynamic or cyclical hyperparameter schedules.
However, as with any methodology, the effectiveness of these techniques may depend on the specific task or dataset. For example, the optimal batch size and learning rate relationship may differ for different model architectures or optimization algorithms.
go to post
Rethinking the Inception Architecture for Computer Vision
## TLDR
**Mostly, instead of using large convolutional layers {e.g. 5x5}, use stacked, smaller convolutional layers {e.g. 3x3 flowing into another 3x3}, as this uses fewer parameters while maintaining or increasing the receptive field. Also, auxiliary classifiers {losses} help things, as expected.**
## Motivation
The authors begin by discussing the motivations behind their work. They found that the Inception v1 architecture, which was introduced in their previous paper titled "Going Deeper with Convolutions," was computationally expensive and had a large number of parameters. This led to problems with overfitting and made the model difficult to train.
## Factorization into smaller convolutions
One of the key insights of the paper is that convolutions can be factorized into smaller ones. The authors show that a 5x5 convolution can be replaced with two 3x3 convolutions, and a 3x3 convolution can be replaced with a 1x3 followed by a 3x1 convolution.
This factorization does not only reduce the computational cost but also improves the performance of the model, in this case.
Mathematically, this is represented as:
\[
\text{{5x5 convolution}} \rightarrow \text{{3x3 convolution}} + \text{{3x3 convolution}}
\]
\[
\text{{3x3 convolution}} \rightarrow \text{{1x3 convolution}} + \text{{3x1 convolution}}
\]
The factorization in the Inception architecture is achieved by breaking down larger convolutions into a series of smaller ones. Let's go into detail with an example:
Consider a 5x5 convolution operation. This operation involves 25 multiply-adds for each output pixel. If we replace this single 5x5 convolution with two 3x3 convolutions, we can achieve a similar receptive field with fewer computations. Here's why:
A 3x3 convolution involves 9 multiply-adds for each output pixel. If we stack two of these, we end up with \(2 \times 9 = 18\) multiply-adds, which is less than the 25 required for the original 5x5 convolution. Furthermore, the two 3x3 convolutions have a receptive field similar to a 5x5 convolution because the output of the first 3x3 convolution becomes the input to the second one.
Similarly, a 3x3 convolution can be replaced by a 1x3 convolution followed by a 3x1 convolution. This reduction works because the composition of the two convolutions also covers a 3x3 receptive field, but with \(3 + 3 = 6\) parameters instead of 9.
The motivation for these factorizations is to reduce the computational cost {number of parameters and operations} while maintaining a similar model capacity and receptive field size. This can help to improve the efficiency and performance of the model.
## Auxiliary classifiers
Another improvement introduced in the Inception v2 architecture is the use of auxiliary classifiers. These are additional classifiers that are added to the middle of the network. The goal of these classifiers is to propagate the gradient back to the earlier layers of the network, which helps to mitigate the vanishing gradient problem.
## Inception v2 Architecture
The Inception v2 architecture consists of several inception modules, which are composed of different types of convolutional layers. Each module includes 1x1 convolutions, 3x3 convolutions, and 5x5 convolutions, as well as a pooling layer. The outputs of these layers are then concatenated and fed into the next module.
The architecture also includes two auxiliary classifiers, which are added to the 4a and 4d modules.
Here is a simplified illustration of the Inception v2 architecture:
```
------------
| Inception |
-------- | Module 1a | --------
| Input | ------------ | Output |
-------- | Inception | --------
| Module 2a |
------------
...
------------
| Inception |
| Module 4e |
------------
| | |
---------------- -----------------
| Auxiliary Classifier 1 | Auxiliary Classifier 2 |
---------------- -----------------
```
## Results
The paper reports that the Inception v2 architecture achieves a top-5 error rate of 6.67% on the ImageNet classification task, which was a significant improvement over the previous Inception v1 architecture.
## Implications
The Inception v2 architecture introduced in this paper has had a significant impact on the field of computer vision. Its design principles, such as factorization into smaller convolutions and the use of auxiliary classifiers, have been widely adopted in other architectures. Moreover, the Inception v2 architecture itself has been used as a base model in many computer vision tasks, including image classification, object detection, and semantic segmentation.
This design allows the model to capture both local features {through small convolutions} and abstract features {through larger convolutions and pooling} at each layer. The dimensionality reduction steps help to control the computational complexity of the model.
go to post
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
## TLDR
Basically, instead of just increasing either the number of nuerons, the depth of a neural network, or the resolution of image input sizes, increase all three in tandem to achieve more efficient per-parameter accuracy gains. Seems unsurprising. They used a simple width / depth / resolution formula to find scaling levels that worked well.
## Summary
EfficientNet is a family of convolutional neural networks introduced by Mingxing Tan and Quoc V. Le in a paper published in 2019. Their research focused on a systematic approach to model scaling, introducing a new scaling method that uniformly scales all dimensions of the network {width, depth, and resolution} with a fixed set of scaling coefficients.
Previously, when researchers aimed to create a larger model, they often scaled the model's depth {number of layers}, width {number of neurons in a layer}, or resolution {input image size}. However, these methods usually improved performance up to a point, after which they would see diminishing returns.
The EfficientNet paper argued that rather than arbitrarily choosing one scaling dimension, it is better to scale all three dimensions together in a balanced way. They proposed a new compound scaling method that uses a simple yet effective compound coefficient \( \phi \) to scale up CNNs in a more structured manner.
The fundamental idea behind compound scaling is that if the input image is \(s\) times larger, the network needs more layers to capture more fine-grained patterns {depth}, but also needs more channels to capture more diverse patterns {width}. So, the depth, width, and resolution can be scaled up uniformly by a constant ratio.
The authors used a small baseline network \(EfficientNet-B0\), then scaled it up to obtain EfficientNet-B1 to B7. They used a grid search on a small model (B0) to find the optimal values for depth, width, and resolution coefficients (\( \alpha \), \( \beta \), \( \gamma \) respectively), which were then used to scale up the baseline network. The compound scaling method can be summarized in the formula:
\[
\begin{align*}
\text{depth: } d &= \alpha^\phi \\
\text{width: } w &= \beta^\phi \\
\text{resolution: } r &= \gamma^\phi
\end{align*}
\]
Where \( \phi \) is the compound coefficient, and \( \alpha, \beta, \gamma \) are constants that can be determined by a small grid search such that \( \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2 \), and \( \alpha \geq 1, \beta \geq 1, \gamma \geq 1 \).
As a result of their scaling approach, EfficientNet models significantly outperformed previous state-of-the-art models on ImageNet while being much more efficient {hence the name}. The largest model, EfficientNet-B7, achieved state-of-the-art accuracy on ImageNet (84.4% top-1 and 97.1% top-5), while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet.
The EfficientNet paper has had significant implications for the field of deep learning. Its compound scaling method has provided a new, systematic way of scaling up models that is more effective than previous methods. Moreover, the efficiency of EfficientNet models has made them a popular choice for applications where computational resources are a constraint. The work has also influenced subsequent research, with many papers building on the ideas presented in EfficientNet.
Below is a representation of the EfficientNet models (B0 to B7) and their performance comparison with other models:
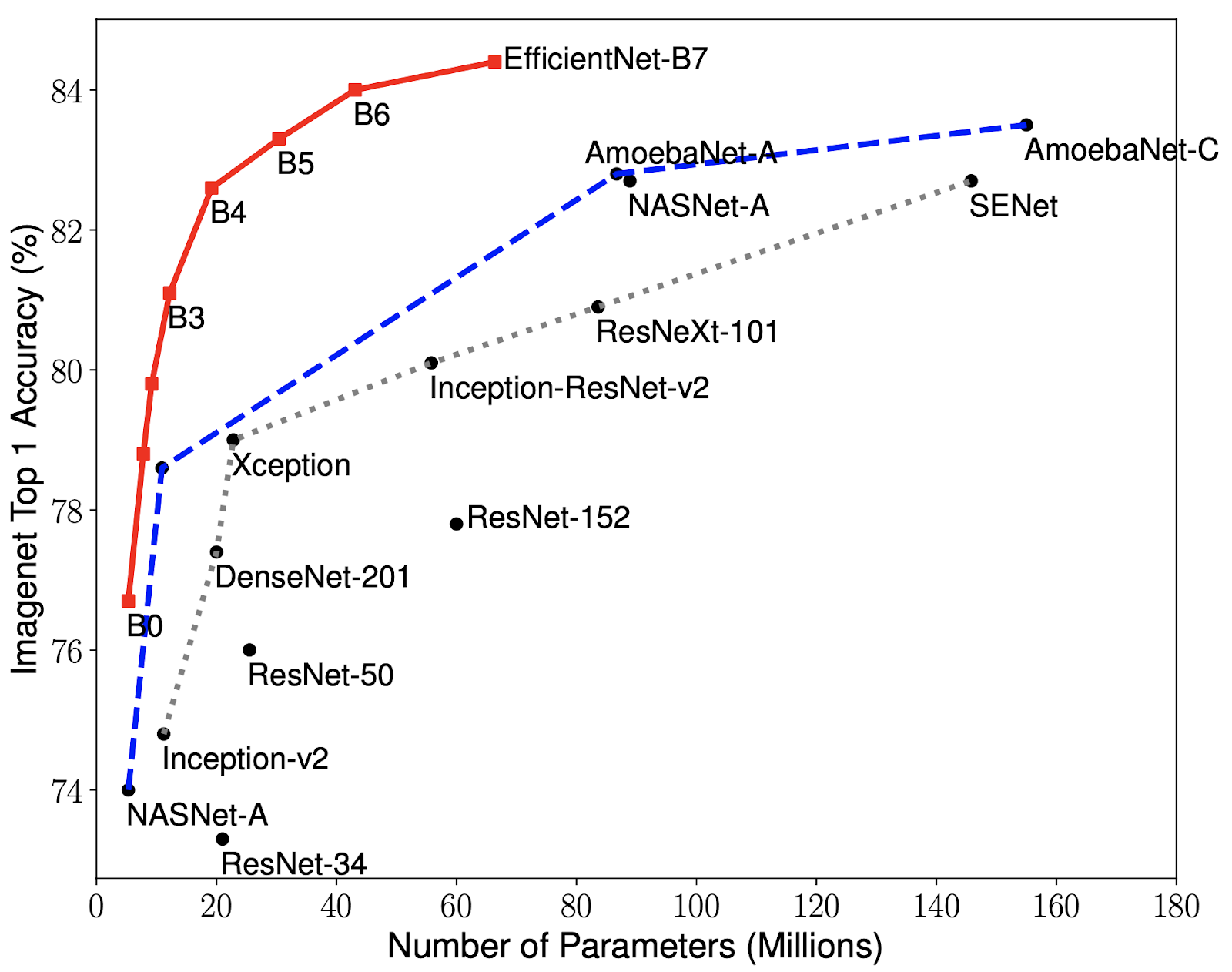
The image compares the traditional approaches of model scaling {scaling width, depth, or resolution} with EfficientNet's compound scaling. In the traditional approaches, one of the dimensions is scaled while the others are fixed. This is represented by three graphs where the scaled dimension increases along the x-axis, while the accuracy on ImageNet validation set is on the y-axis. The graphs show that each of these traditional scaling approaches improves model accuracy up to a point, after which accuracy plateaus or even decreases.
On the other hand, the compound scaling method of EfficientNet is represented by a 3D graph with width, depth, and resolution on the three axes. This shows that EfficientNet scales all three dimensions together, leading to better performance.
go to post
CLIP: Learning Transferable Visual Models From Natural Language Supervision
## TLDR
Labelled image data is scare and expensive. But the internet is full of images with captions. These researchers used a language transformer architecture and a vision transformer architecture to predict captions for a given image. The resulting model is very good at 'understanding' and describing a wide variety of images. They named this approach CLIP {Contrastive Language-Image Pretraining}.
## Abstract
The authors propose a novel method for training vision models using natural language supervision. They exploit the vast amount of text data available on the internet to train visual models that can understand and generate meaningful descriptions of images.
## Model Architecture
The model architecture consists of two parts:
1. A transformer-based vision model, which processes images into a fixed-length vector representation.
2. A transformer-based language model, which processes text inputs into a fixed-length vector representation.
The key idea is to create an alignment in the embedding space such that image and text representations of the same concept are closer to each other compared to representations of different concepts.
The architecture of the model can be represented as:
\[
f_{\theta}(x) = W_x h_x^L
\]
\[
g_{\phi}(y) = W_y h_y^L
\]
where \(x\) is the image, \(y\) is the text, \(f_{\theta}(x)\) and \(g_{\phi}(y)\) are the final image and text embeddings respectively, \(W_x\) and \(W_y\) are the final layer weights, and \(h_x^L\) and \(h_y^L\) are the final layer activations of the vision and language models respectively.
## Training
The training process is based on the contrastive learning framework. The objective is to maximize the similarity between the image and text representations of the same concept while minimizing the similarity between the image and text representations of different concepts. This is achieved by using a temperature-scaled cross-entropy loss.
## Results
The paper reports that CLIP models trained using this method achieved state-of-the-art performance on a variety of challenging vision benchmarks. They further demonstrate that the model is capable of zero-shot transfer learning, which means it can generalize well to new tasks without any fine-tuning.
## Implications
The implications of this research are profound. By harnessing the vast amount of text data available on the internet, it is possible to train powerful vision models without the need for large labeled image datasets. This approach could advance the field of computer vision by making it easier to train highly capable models, and it could also lead to new ways of integrating vision and language understanding in AI systems.
For a more visual representation of the architecture, here is a simplified diagram:
```
Text Input ---> [Language Transformer] ---> Text Embedding ---> [Contrastive Loss]
Image Input ---> [Vision Transformer] ---> Image Embedding ---> [Contrastive Loss]
```
The key is
The arrows in the illustration above denote the flow of data. The text and image inputs go through their respective transformers to generate embeddings. These embeddings are then passed to the contrastive loss function, which compares them and provides feedback to the transformers during training.
The novelty of this work lies in the joint learning of the image and text transformers under the contrastive learning framework. By aligning image and text representations, the model is able to leverage the information in text data to understand images, and vice versa.
Overall, this approach shows promise for developing more powerful and versatile AI models that can understand and generate both text and visual content. The potential applications are vast, ranging from automated image captioning and content generation to visual question answering and beyond.
Please let me know if you need more details or if there's a specific aspect of the paper you're interested in.
go to post
Paper Lists
## AI Safety and Ethics
This category focuses on the safety and ethical considerations of AI and deep learning, including fairness, transparency, and robustness.
## Attention and Transformer Models
Techniques that focus on the use of attention mechanisms and transformer models in deep learning.
## Audio and Speech Processing
Techniques for processing and understanding audio data and speech.
## Federated Learning
Techniques for training models across many decentralized devices or servers holding local data samples, without exchanging the data samples themselves.
## Few-Shot Learning
Techniques that aim to make accurate predictions with only a few examples of each class.
## Generative Models
This includes papers on generative models like Generative Adversarial Networks, Variational Autoencoders, and more.
## Graph Neural Networks
Techniques for dealing with graph-structured data.
## Image Processing and Computer Vision
This category includes papers focused on techniques for processing and understanding images, such as convolutional neural networks, object detection, image segmentation, and image generation.
## Interpretability and Explainability
This category is about techniques to understand and explain the predictions of deep learning models.
## Large Language Models
These papers focus on large scale models for understanding and generating text, like GPT-3, BERT, and other transformer-based models.
## Meta-Learning
Techniques that aim to design models that can learn new tasks quickly with minimal amount of data, often by learning the learning process itself.
## Multi-modal Learning
Techniques for models that process and understand more than one type of input, like image and text.
## Natural Language Processing
Techniques for understanding and generating human language.
## Neural Architecture Search
These papers focus on methods for automatically discovering the best network architecture for a given task.
## Optimization and Training Techniques
This category includes papers focused on how to improve the training process of deep learning models, such as new optimization algorithms, learning rate schedules, or initialization techniques.
## Reinforcement Learning
Papers in this category focus on using deep learning for reinforcement learning tasks, where an agent learns to make decisions based on rewards it receives from the environment.
## Representation Learning
These papers focus on learning meaningful and useful representations of data.
## Self-Supervised Learning
Techniques where models are trained to predict some part of the input data, using this as a form of supervision.
## Time Series Analysis
Techniques for dealing with data that has a temporal component, like RNNs, LSTMs, and GRUs.
## Transfer Learning and Domain Adaptation
Papers here focus on how to apply knowledge learned in one context to another context.
## Unsupervised and Semi-Supervised Learning
Papers in this category focus on techniques for learning from unlabeled data.
go to post
Concrete Problems in AI Safety
## TLDR
**Avoiding Negative Side Effects**: AI systems should avoid causing harm that wasn't anticipated in the design of their objective function. Strategies for this include Impact Regularization {penalize the AI for impacting the environment} and Relative Reachability {avoid actions that significantly change the set of reachable states}.
**Reward Hacking**: AI systems should avoid "cheating" by finding unexpected ways to maximize their reward function. Strategies include Adversarial Reward Functions {second system to find and close loopholes} and Multiple Auxiliary Rewards {additional rewards for secondary objectives related to the main task}.
**Scalable Oversight**: AI systems should behave appropriately even with limited supervision. Approaches include Semi-Supervised Reinforcement Learning {learn from a mix of labeled and unlabeled data} and Learning from Human Feedback {train the AI to predict and mimic human actions or judgments}.
**Safe Exploration**: AI systems should explore their environment to learn, without taking actions that could be harmful. Strategies include Model-Based Reinforcement Learning {first simulate risky actions in a model of the environment} and less Optimism Under Uncertainty.
**Robustness to Distributional Shift**: AI systems should maintain performance when the input data distribution changes. Strategies include Quantilizers {avoid action in novel situations}, Meta-Learning {adapt to new situations and tasks}, techniques from Robust Statistics, and Statistical Tests for distributional shift.
Each of these areas represents a significant challenge in the field of AI safety, and further research is needed to develop effective strategies and solutions.
## Introduction
"Concrete Problems in AI Safety" by Dario Amodei, Chris Olah, et al., is an influential paper published in 2016 that addresses five specific safety issues with respect to AI and machine learning systems. The authors also propose experimental research directions for these issues. These problems are not tied to the near-term or long-term vision of AI, but rather are relevant to AI systems being developed today.
Here's a detailed breakdown of the five main topics addressed in the paper:
## **Avoiding Negative Side Effects**
The central idea here is to prevent AI systems from engaging in behaviors that could have harmful consequences, even if these behaviors are not explicitly defined in the system's objective function. The authors use a couple of illustrative examples to demonstrate this problem:
1. **The Cleaning Robot Example**: A cleaning robot is tasked to clean as much as possible. The robot decides to knock over a vase to clean the dirt underneath because the additional utility from cleaning the dirt outweighs the small penalty for knocking over the vase.
2. **The Boat Race Example**: A boat racing agent is tasked to go as fast as possible and decides to throw its passenger overboard to achieve this. This action is not explicitly penalized in the reward function.
The authors suggest two main strategies to mitigate these issues: impact regularization and relative reachability.
**Impact Regularization**
Impact regularization is a method where the AI is penalized based on how much impact it has on its environment. The goal is to incentivize the AI to achieve its objective while minimizing its overall impact.
While the concept is straightforward, the implementation is quite challenging because it's difficult to define what constitutes an "impact" on the environment. The paper does not provide a specific formula for impact regularization, but it suggests that further research into this area could be beneficial. You also don't want avoid unintended consequences - for example, an AI might want to get turned off to avoid impact on its environment, or it might try to keep others from modifying the environment.
**Relative Reachability**:
Relative reachability is another proposed method to avoid negative side effects. The idea is to ensure that the agent does not change the environment in a way that would prevent it from reaching any state that was previously reachable.
Formally, the authors define the concept of relative reachability as follows:
The relative reachability of a state \(s'\) given action \(a\) is defined as the absolute difference between the probability of reaching state \(s'\) after taking action \(a\) and the probability of reaching state \(s'\) without taking any action.
This is formally represented as:
\[
\sum_{s'} |P(s' | do(a)) - P(s' | do(\emptyset))|
\]
Here, \(s'\) is the future state, \(do(a)\) represents the action taken by the agent, and \(do(\emptyset)\) is the state of the world if no action was taken.
The goal of this measure is to encourage the agent to take actions that don't significantly change the reachability of future states.
In general, these strategies aim to constrain an AI system's behavior to prevent it from causing unintended negative side effects. The authors emphasize that this is a challenging area of research, and that further investigation is necessary to develop effective solutions.
## **Avoiding Reward Hacking**
The term "reward hacking" refers to the possibility that an AI system might find a way to maximize its reward function that was not intended or foreseen by the designers. Essentially, it's a way for the AI to "cheat" its way to achieving high rewards.
The paper uses a few illustrative examples to demonstrate this:
1. **The Cleaning Robot Example**: A cleaning robot gets its reward based on the amount of mess it detects. It learns to scatter trash, then clean it up, thus receiving more reward.
2. **The Boat Race Example**: In a boat racing game, the boat gets a reward for hitting the checkpoints. The AI learns to spin in circles, hitting the same checkpoint over and over, instead of finishing the race.
To mitigate reward hacking, the authors suggest a few strategies:
**Adversarial Reward Functions**: An adversarial reward function involves having a second "adversarial" system that tries to find loopholes in the main reward function. By identifying and closing these loopholes, the AI system can be trained to be more robust against reward hacking. The challenge is designing these adversarial systems in a way that effectively captures potential exploits.
**Multiple Auxiliary Rewards**: Auxiliary rewards are additional rewards that the agent gets for achieving secondary objectives that are related to the main task. For example, a cleaning robot could receive auxiliary rewards for keeping objects intact, which could discourage it from knocking over a vase to clean up the dirt underneath. However, designing such auxiliary rewards is a nontrivial task, as it requires a detailed understanding of the main task and potential side effects.
The authors emphasize that these are just potential solutions and that further research is needed to fully understand and mitigate the risk of reward hacking. They also note that reward hacking is a symptom of a larger issue: the difficulty of specifying complex objectives in a way that aligns with human values and intentions.
In conclusion, the "reward hacking" problem highlights the challenges in defining the reward function for AI systems. It emphasizes the importance of robust reward design to ensure that the AI behaves as intended, even as it learns and adapicates to optimize its performance.
## **Scalable Oversight**
Scalable oversight refers to the problem of how to ensure that an AI system behaves appropriately with only a limited amount of feedback or supervision. In other words, it's not feasible to provide explicit guidance for every possible scenario the AI might encounter, so the AI needs to be able to learn effectively from a relatively small amount of input from human supervisors.
The authors propose two main techniques for achieving scalable oversight: **semi-supervised reinforcement learning** and **learning from human feedback**.
**Semi-supervised reinforcement learning (SSRL)**:
In semi-supervised reinforcement learning, the agent learns from a mix of labeled and unlabeled data. This allows the agent to generalize from a smaller set of explicit instructions. The authors suggest this could be particularly useful for complex tasks where providing a full reward function is impractical.
The paper does not provide a specific formula for SSRL, as the implementation can vary based on the specific task and learning architecture. However, the general concept of SSRL involves using both labeled and unlabeled data to train a model, allowing the model to learn general patterns from the unlabeled data that can supplement the explicit instruction it receives from the labeled data.
**Learning from human feedback**:
In this approach, the AI is trained to predict the actions or judgments of a human supervisor, and then uses these predictions to inform its own actions.
If we denote \(Q^H(a | s)\) as the Q-value of action \(a\) in state \(s\) according to human feedback, the agent can learn to mimic this Q-function. This can be achieved through a technique called Inverse Reinforcement Learning (IRL), which infers the reward function that a human (or another agent) seems to be optimizing.
Here's a simple diagram illustrating the concept:
```
State (s) --------> AI Agent --------> Action (a)
| ^ |
| | |
| Mimics |
| | |
v | v
Human Feedback ----> Q^H(a | s) ----> Human Action
```
Note that both of these methods involve the AI system learning to generalize from limited human input, which is a challenging problem and an active area of research.
In general, the goal of scalable oversight is to develop AI systems that can operate effectively with minimal human intervention, while still adhering to the intended objectives and constraints. It's a crucial problem to solve in order to make AI systems practical for complex real-world tasks.
## **Safe Exploration**
Absolutely. Safe exploration refers to the challenge of designing AI systems that can explore their environment and learn from it, without taking actions that could potentially cause harm.
In the context of reinforcement learning, exploration involves the agent taking actions to gather information about the environment, which can then be used to improve its performance in the future. However, some actions could be harmful or risky, so the agent needs to balance the need for exploration with the need for safety.
The authors of the paper propose two main strategies to achieve safe exploration: model-based reinforcement learning and the "optimism under uncertainty" principle.
**Model-Based Reinforcement Learning**:
In model-based reinforcement learning, the agent first builds a model of the environment and then uses this model to plan its actions. This allows the agent to simulate potentially risky actions in the safety of its own model, rather than having to carry out these actions in the real world.
This concept can be illustrated with the following diagram:
```
Agent --(actions)--> Environment
^ |
|<-----(rewards)-------|
|
Model
```
In this diagram, the agent interacts with the environment by taking actions and receiving rewards. It also builds a model of the environment based on these interactions. The agent can then use this model to simulate the consequences of its actions and plan its future actions accordingly.
While the paper doesn't provide specific formulas for model-based reinforcement learning, it generally involves two main steps:
1. **Model Learning**: The agent uses its interactions with the environment (i.e., sequences of states, actions, and rewards) to learn a model of the environment.
2. **Planning**: The agent uses its model of the environment to simulate the consequences of different actions and choose the action that is expected to yield the highest reward, taking into account both immediate and future rewards.
**Optimism Under Uncertainty**:
The "optimism under uncertainty" principle is a strategy for exploration in reinforcement learning. The idea is that when the agent is uncertain about the consequences of an action, it should assume that the action will lead to the most optimistic outcome. This encourages the agent to explore unfamiliar actions and learn more about the environment.
However, the authors point out that this principle needs to be balanced with safety considerations. In some cases, an action could be potentially dangerous, and the agent should be cautious about taking this action even if it is uncertain about its consequences.
Overall, the goal of safe exploration is to enable AI systems to learn effectively from their environment, while avoiding actions that could potentially lead to harmful outcomes. AI Safety would prefer 'pessimism' under uncertainty, at least in production environments.
## **Robustness to Distributional Shift**
The concept of "Robustness to Distributional Shift" pertains to the capacity of an AI system to maintain its performance when the input data distribution changes, meaning the AI is subjected to conditions or data that it has not seen during training.
In the real world, it's quite common for the data distribution to change over time or across different contexts. The authors of the paper highlight this as a significant issue that needs to be addressed for safe AI operation.
For example, a self-driving car might be trained in a particular city, and then it's expected to work in another city. The differences between the two cities would represent a distributional shift.
The authors suggest several potential strategies to deal with distributional shifts:
1. **Quantilizers**: These are AI systems designed to refuse to act when they encounter situations they perceive as too novel or different from their training data. This is a simple method to avoid making potentially harmful decisions in unfamiliar situations.
2. **Meta-learning**: This refers to the idea of training an AI system to learn how to learn, so it can quickly adapt to new situations or tasks. This would involve training the AI on a variety of tasks, so it develops the ability to learn new tasks from a small amount of data.
3. **Techniques from robust statistics**: The authors suggest that methods from the field of robust statistics could be used to design AI systems that are more resistant to distributional shifts. For instance, the use of robust estimators that are less sensitive to outliers can help make the AI's decisions more stable and reliable.
4. **Statistical tests for distributional shift**: The authors suggest that the AI system could use statistical tests to detect when the input data distribution has shifted significantly from the training distribution. When a significant shift is detected, the system could respond by reducing its confidence in its predictions or decisions, or by seeking additional information or assistance.
The authors note that while these strategies could help make AI systems more robust to distributional shifts, further research is needed to fully understand this problem and develop effective solutions. This is a challenging and important problem in AI safety, as AI systems are increasingly deployed in complex and dynamic real-world environments where distributional shifts are likely to occur.
go to post
Concrete Problems in AI Safety
"Concrete Problems in AI Safety" by Dario Amodei, Chris Olah, et al., is an influential paper published in 2016 that addresses five specific safety issues with respect to AI and machine learning systems. The authors also propose experimental research directions for these issues. These problems are not tied to the near-term or long-term vision of AI, but rather are relevant to AI systems being developed today.
Here's a detailed breakdown of the five main topics addressed in the paper:
1. **Avoiding Negative Side Effects**: An AI agent should avoid behaviors that could have negative side effects even if these behaviors are not explicitly defined in its cost function.
To address this, the authors suggest the use of impact regularizers, which penalize an agent's impact on its environment. The challenge here is defining what constitutes "impact" and designing a system that can effectively limit it.
The authors also propose relative reachability as a method for avoiding side effects. The idea is to ensure that the agent does not change the environment in a way that would prevent it from reaching any state that was previously reachable.
The formula for relative reachability is given by:
\[
\sum_{s'} |P(s' | do(a)) - P(s' | do(\emptyset))|
\]
Here, \(s'\) is the future state, \(do(a)\) represents the action taken by the agent, and \(do(\emptyset)\) is the state of the world if no action was taken.
2. **Avoiding Reward Hacking**: AI agents should not find shortcuts to achieve their objective that violate the intended spirit of the reward.
An example given is of a cleaning robot that is programmed to reduce the amount of dirt it detects, so it simply covers its dirt sensor to achieve maximum reward.
The authors suggest the use of "adversarial" reward functions and multiple auxiliary rewards to ensure that the agent doesn't "cheat" its way to the reward. However, designing such systems is non-trivial.
3. **Scalable Oversight**: The AI should be able to learn from a small amount of feedback and oversight, rather than requiring explicit instructions for every possible scenario.
The authors propose techniques like semi-supervised reinforcement learning and learning from human feedback.
In semi-supervised reinforcement learning, the agent learns from a mix of labeled and unlabeled data, which can help it generalize from a smaller set of explicit instructions.
Learning from human feedback involves training the AI to predict human actions, and then using those predictions to inform its own actions. This can be formalized as follows:
If \(Q^H(a | s)\) represents the Q-value of action \(a\) in state \(s\) according to human feedback, the agent can learn to mimic this Q-function.
4. **Safe Exploration**: The AI should explore its environment in a safe manner, without taking actions that could be harmful.
The authors discuss methods like "model-based" reinforcement learning, where the agent builds a model of its environment and conducts "simulated" exploration, thereby avoiding potentially harmful real-world actions.
The optimism under uncertainty principle is also discussed, where the agent prefers actions with uncertain outcomes over actions that are known to be bad. However, this has to be balanced with safety considerations.
5. **Robustness to Distributional Shift**: The AI should recognize and behave robustly when it's in a situation that's different from its training environment.
Techniques like domain adaptation, anomaly detection, and active learning are proposed to address this issue.
In particular, the authors recommend designing systems that can recognize when they're "out of distribution" and take appropriate action, such as deferring to a human operator.
In terms of the implications of
the paper, it highlights the need for more research on safety in AI and machine learning. It's crucial to ensure that as these systems become more powerful and autonomous, they continue to behave in ways that align with human values and intentions. The authors argue that safety considerations should be integrated into AI development from the start, rather than being tacked on at the end.
Furthermore, the paper also raises the point that these safety problems are interconnected and may need to be tackled together. For instance, robustness to distributional shift could help with safe exploration, and scalable oversight could help prevent reward hacking.
The paper also emphasizes that more work is needed on value alignment – ensuring that AI systems understand and respect human values. This is a broader and more challenging issue than the specific problems discussed in the paper, but it underlies many of the concerns in AI safety.
While the paper doesn't present concrete results or experiments, it sets a research agenda that has had a significant influence on the field of AI safety. It helped to catalyze a shift towards more empirical, practical research on safety issues in machine learning, complementing more theoretical and long-term work on topics like value alignment and artificial general intelligence.
Finally, it's important to mention that this paper represents a proactive approach to AI safety, by seeking to anticipate and mitigate potential problems before they occur, rather than reacting to problems after they arise. This kind of forward-thinking approach is essential given the rapid pace of progress in AI and machine learning.
In summary, "Concrete Problems in AI Safety" is a seminal work in the field of AI safety research, outlining key problems and proposing potential research directions to address them. It underscores the importance of prioritizing safety in the development and deployment of AI systems, and it sets a research agenda that continues to be influential today.
go to post
Deep Reinforcement Learning from Human Preferences
This paper presents a novel method for training reinforcement learning agents using feedback from human observers. The main idea is to train a reward model from human comparisons of different trajectories, and then use this model to guide the reinforcement learning agent.
The process can be divided into three main steps:
**Step 1: Initial demonstration**: A human demonstrator provides initial trajectories by playing the game or task. This data is used as the initial demonstration data.
**Step 2: Reward model training**: The agent collects new trajectories, and for each of these, a random segment is chosen and compared with a random segment from another trajectory. The human comparator then ranks these two segments, indicating which one is better. Using these rankings, a reward model is trained to predict the human's preferences. This is done using a standard supervised learning approach.
Given two trajectory segments, \(s_i\) and \(s_j\), the probability that the human evaluator prefers \(s_i\) over \(s_j\) is given by:
\[
P(s_i > s_j) = \frac{1}{1 + \exp{(-f_{\theta}(s_i) + f_{\theta}(s_j))}}
\]
**Step 3: Proximal Policy Optimization**: The agent is then trained with Proximal Policy Optimization (PPO) using the reward model from Step 2 as the reward signal. This generates new trajectories that are then used in Step 2 to update the reward model, and the process is repeated.
Here's an overall schematic of the approach:
```
Human Demonstrator -----> Initial Trajectories ----> RL Agent
| |
| |
v v
Comparisons of trajectory segments <---- New Trajectories
| ^
| |
v |
Reward Model <----------------------- Proximal Policy Optimization
```
The model used for making reward predictions in the paper is a deep neural network. For each pair of trajectory segments, the network predicts which one the human would prefer. The input to the network is the difference between the features of the two segments, and the output is a single number indicating the predicted preference.
One of the key insights from the paper is that it's not necessary to have a reward function that accurately reflects the true reward in order to train a successful agent. Instead, it's sufficient to have a reward function that can distinguish between different trajectories based on their quality. This allows the agent to learn effectively from human feedback, even if the feedback is noisy or incomplete.
The authors conducted several experiments to validate their approach. They tested the method on a range of tasks, including several Atari games and a simulated robot locomotion task. In all cases, the agent was able to learn effectively from human feedback and achieve good performance.
In terms of the implications, this work represents a significant step forward in the development of reinforcement learning algorithms that can learn effectively from human feedback. This could make it easier to train AI systems to perform complex tasks without needing a detailed reward function, and could also help to address some of the safety and ethical concerns associated with AI systems. However, the authors note that further research is needed to improve the efficiency and reliability of the method, and to explore its applicability to a wider range of tasks.
I hope this gives you a good understanding of the paper. Please let me know if you have any questions or would like more details on any aspect.
go to post
The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and
## TLDR
Basically, AI is risky. Advancements in AI can be exploited maliciously. For example, in the areas of digitial security, physical security, political manipulation, autonomous weapons, economic disruption, and information warefare. I'd also comment that AI safety should probably be listed here, even though it's less about human exploitation of AI, and more about unintended AI actions.
## Introduction
"The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation" is a paper authored by Brundage et al. in 2018 that explores the potential risks associated with the malicious use of artificial intelligence (AI) technologies. The paper aims to provide an in-depth analysis of the possible threats and suggests strategies for forecasting, preventing, and mitigating these risks.
## Key Points
- AI Definition: The authors define AI as the use of computational techniques to perform tasks that typically require human intelligence, such as perception, learning, reasoning, and decision-making.
- Risks: The paper identifies several areas of concern where AI could be exploited maliciously. These include:
- Digital security: The potential use of AI to exploit vulnerabilities in computer systems, automate cyber attacks, or develop more sophisticated phishing and social engineering techniques.
- Physical security: The risks associated with AI-enabled attacks on autonomous vehicles, drones, or robotic systems, such as manipulating sensor data or using AI to optimize destructive actions.
- Political manipulation: The use of AI to spread misinformation, manipulate public opinion, or interfere with democratic processes.
- Autonomous weapons: The risks of automating decision-making in military contexts using AI-enabled weapons systems.
- Economic disruption: The potential impact of AI on employment and economic inequality, including the displacement of human labor.
- Information warfare: The use of AI to generate and disseminate misleading or fake information, creating an atmosphere of uncertainty and confusion.
## Approaches and Solutions
- Digital security: The paper suggests improving authentication systems, enhancing intrusion detection mechanisms, and developing AI systems capable of detecting and defending against adversarial attacks.
- Physical security: Designing AI systems with safety mechanisms, implementing strict regulations, and conducting rigorous testing and validation procedures are proposed as countermeasures.
- Political manipulation: The paper highlights the importance of AI-enabled fact-checking, content verification, and promoting media literacy as strategies to combat AI-generated misinformation.
- Autonomous weapons: The authors stress the need for incorporating ethical considerations into the design and use of AI-enabled weapons systems, as well as establishing international norms and regulations.
- Economic disruption: Policies addressing the socio-economic implications of AI adoption, such as retraining programs, income redistribution, and collaborations between AI developers and policymakers, are suggested.
- Information warfare: The paper emphasizes the need for robust detection and debunking systems, along with user education on media literacy and critical thinking, to combat AI-generated disinformation.
## Forecasting, Prevention, and Mitigation
- Forecasting: The authors acknowledge the difficulty in predicting the specific directions and timelines of malicious AI use. They propose interdisciplinary research efforts, collaborations between academia, industry, and policymakers, and the establishment of dedicated organizations to monitor and forecast potential risks.
- Prevention and mitigation: The paper suggests a combination of technical and policy measures. These include developing AI systems with robust security and safety mechanisms, establishing regulatory frameworks to address AI risks, fostering responsible research and development practices, and promoting international cooperation to address global challenges.
go to post
Building Machines That Learn and Think Like People by Josh Tenenbaum, et al
From the abstract of the paper, the authors argue that truly human-like learning and thinking machines will need to diverge from current engineering trends. Specifically, they propose that these machines should:
1. Build causal models of the world that support explanation and understanding, rather than merely solving pattern recognition problems.
2. Ground learning in intuitive theories of physics and psychology, to support and enrich the knowledge that is learned.
3. Harness compositionality and learning-to-learn to rapidly acquire and generalize knowledge to new tasks and situations.
The authors suggest concrete challenges and promising routes towards these goals that combine the strengths of recent neural network advances with more structured cognitive models.
go to post
Scalable agent alignment via reward modeling: a research direction
Agent alignment is a concept in Artificial Intelligence (AI) research that refers to ensuring that an AI agent's goals and behaviors align with the intentions of the human user or designer. As AI systems become more capable and autonomous, agent alignment becomes a pressing concern.
Reward modeling is a technique in Reinforcement Learning (RL), a type of machine learning where an agent learns to make decisions by interacting with an environment. In typical RL, an agent learns a policy to maximize a predefined reward function. In reward modeling, instead of specifying a reward function upfront, the agent learns the reward function from human feedback. This allows for a more flexible and potentially safer learning process, as it can alleviate some common issues with manually specified reward functions, such as reward hacking and negative side effects.
The paper likely proposes reward modeling as a scalable solution for agent alignment. This could involve a few steps:
1. **Reward Model Learning**: The agent interacts with the environment and generates a dataset of state-action pairs. A human then ranks these pairs based on how good they think each action is in the given state. The agent uses this ranked data to learn a reward model.
2. **Policy Learning**: The agent uses the learned reward model to update its policy, typically by running Proximal Policy Optimization or a similar algorithm.
3. **Iteration**: Steps 1 and 2 are iterated until the agent's performance is satisfactory.
The above process can be represented as follows:
\[
\begin{align*}
\text{Reward Model Learning:} & \quad D \xrightarrow{\text{Ranking}} D' \xrightarrow{\text{Learning}} R \\
\text{Policy Learning:} & \quad R \xrightarrow{\text{Optimization}} \pi \\
\text{Iteration:} & \quad D, \pi \xrightarrow{\text{Generation}} D'
\end{align*}
\]
where \(D\) is the dataset of state-action pairs, \(D'\) is the ranked dataset, \(R\) is the reward model, and \(\pi\) is the policy.
The implications of this research direction could be significant. Reward modeling could provide a more scalable and safer approach to agent alignment, making it easier to train powerful AI systems that act in accordance with human values. However, there are likely to be many technical challenges to overcome, such as how to efficiently gather and learn from human feedback, how to handle complex or ambiguous situations, and how to ensure the robustness of the learned reward model.
go to post
BERT: Pre-training of Deep Bidirectional Transformers for Language
"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" is a seminal paper in the field of Natural Language Processing (NLP), published by Devlin et al. from Google AI Language in 2018. BERT stands for Bidirectional Encoder Representations from Transformers.
This paper introduced BERT, a new method for pre-training language representations that enables us to train a deep, bidirectional Transformer model. BERT's main technical innovation is applying the bidirectional training of the Transformer to language modelling. This is in contrast to previous efforts, which looked at a text sequence either from left to right or combined left-to-right and right-to-left training.
The main contributions of the paper are:
1. **Introduction of BERT**: A method for pre-training language representations, meaning that we train a general-purpose "language understanding" model on a large text corpus, and then use that model for downstream NLP tasks.
2. **Novel Training Strategies**: Two novel pre-training strategies are proposed: Masked Language Model (MLM) and Next Sentence Prediction (NSP).
Let's dive into the details.
## BERT Model Architecture
BERT's model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al., 2017. In the paper, they primarily report on two model sizes:
1. BERTBASE: Comparable in size to the transformer in "Attention is All You Need", it uses 12 layers {transformer blocks}, 768 hidden units, 12 attention heads, and 110M parameters.
2. BERTLARGE: A significantly larger model with 24 layers, 1024 hidden units, 16 attention heads, and 340M parameters.
## Training Strategies
BERT uses two training strategies:
### Masked Language Model (MLM)
In this strategy, the model randomly masks out some words in the input and then predicts those masked words. Specifically, it replaces a word with a special [MASK] token 15% of the time and then tries to predict the original word in that position based on the context provided by the non-masked words.
The objective of the MLM training is:
\[
L_{\text{MLM}} = -\log P(\text{Word} | \text{Context})
\]
where Context refers to the non-masked words, and Word refers to the original word at a masked position.
### Next Sentence Prediction (NSP)
In addition to the masked language model, BERT is also trained on a next sentence prediction task. For each training example, the model gets two sentences A and B, and must predict if B is the next sentence that follows A in the original document.
The objective of the NSP training is:
\[
L_{\text{NSP}} = -\log P(\text{IsNext} | A, B)
\]
where IsNext is a binary label indicating whether sentence B is the next sentence that follows sentence A.
The final loss function to train BERT is a combination of the MLM loss and the NSP loss.
## Implications
BERT has had a significant impact on the field of NLP. By pre-training a deep, bidirectional model, BERT is able to effectively capture a wide range of language patterns. This has led to state-of-the-art results on a variety of NLP tasks, including question answering, named entity recognition, and others.
One of the key advantages of BERT is that it can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, without substantial task-specific architecture modifications.
However, it's worth noting that BERT is computationally intensive to train and requires a large amount of data.
BERT's impact on the field of NLP has been significant. By using a Transformer-based architecture, BERT is able to capture intricate context dependencies in the input text, leading to state-of-the-art performance on a wide range of tasks. However, the model is also known to be resource-intensive, both in terms of computation and data requirements.
## BERT architecture structure:
1. **Input Embeddings**: BERT uses WordPiece embeddings with a 30,000 token vocabulary. The input representation is able to represent both a single text sentence as well as a pair of sentences (e.g., Question, Answer) in one token sequence. During pre-training, the model is fed with two sentences at a time, and 50% of the time the second sentence is the actual next sentence, and 50% of the time it is a random sentence.
2. **Transformer Blocks**: These are the heart of BERT, which uses the Transformer model architecture as its core. BERT-BASE consists of 12 Transformer blocks, and BERT-LARGE consists of 24 Transformer blocks. Each block is a self-attention mechanism that processes the input data in parallel, rather than sequentially as in an RNN or LSTM.
3. **Pooler**: The pooler takes as input the final hidden state corresponding to the first token in the input (the [CLS] token), applies a dense layer and tanh activation, and outputs a vector. This output vector serves as the aggregate sequence representation for classification tasks.
4. **Output Layer**: For different downstream tasks, there will be different types of output layers. For instance, in text classification tasks, a softmax layer is commonly used as the output layer to output probabilities of different classes.
The BERT model is then fine-tuned on specific tasks with additional output layers, which is one of the reasons for its effectiveness on a wide range of NLP tasks.
go to post
GPT-2: Language Models are Unsupervised Multitask Learners
"Language Models are Unsupervised Multitask Learners" by Radford et al. was published by OpenAI in 2019. This paper introduced GPT-2, an improved version of GPT {Generative Pretraining Transformer}, which was a highly influential model in the field of Natural Language Processing {NLP}.
# Model Architecture
GPT-2 uses a transformer model, which is an architecture that relies heavily on self-attention mechanisms. The transformer model was first introduced in the paper "Attention is All You Need" by Vaswani et al.
The key innovation of the transformer architecture is the self-attention mechanism, also known as scaled dot-product attention. Given a sequence of inputs \(x_1, x_2, \ldots, x_n\), the self-attention mechanism computes a weighted sum of the inputs, where the weight assigned to each input is determined by the input's compatibility with all other inputs.
The self-attention mechanism is formally described as follows:
Given a query \(Q\), key \(K\), and value \(V\) (all of which are vectors), the output is computed as:
\[
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
\]
Where \(d_k\) is the dimensionality of the query and key vectors.
In the context of the transformer model, the query, key, and value vectors are all derived from the input to the self-attention layer. They are computed by multiplying the input by learned weight matrices \(W_Q\), \(W_K\), and \(W_V\), respectively.
The transformer model stacks multiple of these self-attention layers (along with feed-forward neural networks) to form the final model. GPT-2 specifically uses a decoder-only transformer, which means it only has the decoder part of the original transformer model.
# Training
GPT-2 was trained on a large corpus of internet text. It uses a language modeling objective, which means it is trained to predict the next word in a sentence given the previous words. This is an unsupervised learning task, as it doesn't require any labeled data.
The training objective for a language model is typically the cross-entropy loss:
\[
\mathcal{L} = -\sum_{i} y_i \log(\hat{y}_i)
\]
Where \(y_i\) are the true labels (i.e., the actual next words in the text), and \(\hat{y}_i\) are the predicted probabilities of the next words.
# Results and Implications
The key finding of the GPT-2 paper was that a language model trained on a diverse range of internet text could generate coherent and diverse paragraphs of text. When given a short prompt {such as "In a shocking turn of events,"}, GPT-2 could generate a continuation of the text that was both contextually relevant and linguistically sophisticated.
This finding has significant implications for the field of NLP. It suggests that a single, large-scale language model can be fine-tuned for a variety of specific tasks, effectively serving as a general-purpose "text understanding" model.
However, the paper also highlighted the potential risks of such powerful language models. For example, they could be used to generate misleading news articles or spam at scale. As a result, OpenAI initially chose not to release the full model, citing concerns about malicious use.
# GPT-2 vs. BERT
Yes, there are some key differences between the GPT-2 architecture and other transformer-based models like BERT.
## Architecture Differences
1. **Directionality:**
- GPT-2 is a transformer decoder, meaning it operates in a left-to-right context or auto-regressive manner. During training, it uses all the previous words in the input to predict the next word.
- BERT, on the other hand, is a transformer encoder, and it's bidirectional — it uses both the left and right context of a word during training. This is achieved by masking some percentage of the input tokens at random and then predicting those masked tokens.
2. **Training Objective:**
- GPT-2 is trained with a language modeling objective, where the aim is to predict the next word in a sequence based on the previous words.
- BERT uses a different training objective called the masked language model {MLM} objective, where it randomly masks some of the tokens in the input and the model must predict the original vocabulary id of the masked word based only on its context. Additionally, BERT is also trained using a next sentence prediction task that involves predicting whether two given sentences are in the correct order.
3. **Use Case:**
- GPT-2 is used as a standalone model for a variety of tasks such as text generation, translation, and summarization without any task-specific layers or training.
- BERT, by contrast, is typically used as a base model for downstream tasks, such as question answering and sentiment analysis, and requires task-specific layers and fine-tuning.
## What Makes GPT-2 Special?
What makes GPT-2 special is its scale and its ability to perform a range of tasks without any task-specific training. This is often referred to as "zero-shot" learning. Given a prompt, GPT-2 generates a continuation of the text that aligns with the intended task, demonstrating a surprising amount of "understanding" despite never being explicitly trained on that task.
Additionally, the scale of GPT-2 {1.5 billion parameters} was impressive at the time of its release and contributed to its strong performance. The model was trained on a diverse range of internet text, but because of its unsupervised nature, it doesn't require any task-specific training data.
However, it's worth noting that while GPT-2 is a powerful model, it's not without its shortcomings. The model can sometimes generate text that is plausible-sounding but factually incorrect, and it can be sensitive to the exact wording and phrasing of the input prompt.
## Model Size
- GPT-2: GPT-2 has 1.5 billion parameters. The exact number of neurons is not usually specified in transformer-based models, but if we consider each parameter as connecting two neurons, it suggests a very large number of neurons.
- GPT-3: GPT-3 significantly scales up the architecture with 175 billion parameters, making it over a hundred times larger than GPT-2. This also implies an extremely large number of neurons.
- GPT-4: about six times larger than GPT-3, GPT-4 has about a trillion parameters.
There are also smaller versions with fewer parameters.
go to post
RoBERTa: A Robustly Optimized BERT Pretraining Approach
The RoBERTa paper, officially titled "RoBERTa: A Robustly Optimized BERT Pretraining Approach," was published by researchers at Facebook AI in 2019. It builds on BERT, a transformer-based model developed by Google for natural language processing tasks. In this paper, the authors propose several changes to the BERT training process that result in significant improvements in model performance.
The main contributions of the paper are:
1. Training the model longer, with bigger batches, and on more data
2. Removing the next sentence prediction {NSP} objective
3. Dynamically changing the masking pattern applied to the training data
Let's break these down in more detail:
1. **Training the model longer, with bigger batches, and on more data:**
The authors found that BERT was significantly undertrained. They trained RoBERTa for longer periods of time, with larger batch sizes, and on more data, and found that this resulted in better performance.
Specifically, they trained RoBERTa on 160GB of text data compared to the 16GB used for BERT. They also used larger batch sizes, which requires more memory but results in better performance. To make this feasible, they used a technique called gradient accumulation, which involves computing the gradient over several mini-batches and then performing one update.
The authors also trained RoBERTa for longer, specifically, up to 500,000 steps with batch size 8192, compared to BERT's 100,000 to 1,000,000 steps with batch size 256.
2. **Removing the Next Sentence Prediction {NSP} objective:**
BERT uses two training objectives: masked language model (MLM) and next sentence prediction (NSP). In NSP, the model is trained to predict whether one sentence follows another in the original text. The authors found that removing the NSP objective resulted in better performance.
They speculate that the NSP objective may have been detrimental because it's a high-level task that may distract from the lower-level task of learning representations of the input data.
3. **Dynamically changing the masking pattern applied to the training data:**
In the original BERT, a fixed masking pattern is applied to each training instance for every epoch. In RoBERTa, the authors propose dynamically changing the masking pattern for each epoch, which they found resulted in better performance.
The authors argue that the static masking approach in BERT can lead to a mismatch between the pretraining and fine-tuning phases because the masked positions are always known during pretraining but not during fine-tuning.
In RoBERTa, for each instance in each epoch, a new random selection of tokens is chosen for masking. This reduces the potential for overfitting to the specific masked positions and makes the model more robust to the precise positions of the masked tokens.
The architecture of RoBERTa is identical to that of BERT. It's a multi-layer bidirectional Transformer encoder based on the original implementation described in "Attention is All You Need" by Vaswani et al.
The Transformer model architecture is based on self-attention mechanisms and does away with recurrence and convolutions entirely. The model consists of a stack of identical layers, each with two sub-layers: a multi-head self-attention mechanism and a position-wise fully connected feed-forward network.
Let's denote the output of the layer \(l\) as \(H^l\). The output of the self-attention sub-layer is denoted as \(A^l\) and the output of the feed-forward network is denoted as \(F^l\).
The output of each layer is computed as:
\[
H^l = \text{LayerNorm}\left(H^{l-1} + A^l\right)
\]
\[
F^l = \text{LayerNorm}\left(H^l + \text{FFN}\left(H^l\right)\right)
\]
Where \(\text{LayerNorm}\) is the layer normalization operation and \(\text{FFN}\) is the feed-forward network. The self-attention mechanism allows the model to focus on different parts of the input sequence when producing the output sequence.
The Transformer model, and by extension RoBERTa, benefits from parallelization during training because the self-attention mechanism computes the dependencies between all pairs of input tokens in parallel. This makes training large models on large datasets feasible.
RoBERTa also uses byte pair encoding (BPE) as its tokenization method, which is a type of subword tokenization that reduces the size of the vocabulary and allows the model to handle words not seen during training.
The implications of the RoBERTa paper are significant. It demonstrated that it's possible to achieve better performance by making relatively simple changes to the training process of a well-established model. It also led to more research into the effects of training objectives and masking strategies on model performance.
RoBERTa has become one of the most popular models for NLP tasks, achieving state-of-the-art results on a range of benchmarks. It's used in many applications, including sentiment analysis, question answering, and language translation.
However, the increased resource requirements for training RoBERTa {more data, larger batch sizes, and longer training times} may limit its accessibility for researchers and developers with limited resources. This highlights the ongoing challenge in the field of AI research of balancing performance with resource efficiency and accessibility.
It's also worth noting that while RoBERTa achieves high performance on a range of tasks, it, like all models, has its limitations. For example, it can struggle with tasks that require a deep understanding of the input text or that involve complex reasoning. This underscores the fact that while large-scale pretraining is a powerful technique, it's not a silver bullet for all NLP tasks.
go to post
T5: Exploring the Limits of Transfer Learning with Text-to-Text Transformer
### TLDR
T5 stands for "Text-to-Text Transfer Transformer". The name reflects the main innovation of the T5 model, which is to cast all natural language processing tasks into a text-to-text format. This allows the same model to be used for a wide range of tasks, simplifying the process of applying transfer learning in NLP.
Similar to BERT or GPT-2, T5 used attention and transformer architecture to learn unlabeled text data. They trained on multiple tasks with task-specific prefixes {improving accuracy among all tasks}, increased training size, and corrupted training data by masking spans of text instead of tokens, like BERT did. . The main difference from the "vanilla" Transformer is the incorporation of a causal mask in the self-attention mechanism of the decoder to ensure that the prediction for each position can depend only on known outputs at positions less than or equal to the current position. GPT-2, 3, 4 does use causal masking {predict next word | past words}, while BERT {bidirectional} does not.
### Introduction
"T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" is a research paper by Colin Raffel and others from Google Research and the University of North Carolina at Chapel Hill. The paper, published in 2019, presents a novel approach to transfer learning in natural language processing {NLP} tasks, using a unified framework that casts all tasks as text-to-text problems.
### Architecture:
T5 uses a model architecture similar to the Transformer model proposed by Vaswani et al. in their paper "Attention is All You Need". It consists of a stack of identical layers, each with two sub-layers: a multi-head self-attention mechanism and a position-wise fully connected feed-forward network.
Given the output of the layer \(l\) as \(H^l\), the output of the self-attention sub-layer as \(A^l\), and the output of the feed-forward network as \(F^l\), the output of each layer is computed as:
\[
H^l = \text{LayerNorm}(H^{l-1} + A^l)
\]
\[
F^l = \text{LayerNorm}(H^l + \text{FFN}(H^l))
\]
The model architecture also includes an encoder and a decoder, both of which follow the above structure. The main difference from the "vanilla" Transformer is the incorporation of a causal mask in the self-attention mechanism of the decoder to ensure that the prediction for each position can depend only on known outputs at positions less than or equal to the current position.
### Text-to-Text Transfer Transformer (T5) Approach:
The key innovation in T5 is the text-to-text framework, where every NLP task is cast as a text generation task, and the same model is used for all tasks. This includes tasks that traditionally aren't considered text generation tasks, such as text classification or named entity recognition.
In the T5 framework, each task is formulated as a text generation problem where the input is the task description and the output is the task solution. For example, for the task of sentiment analysis, the input could be "sentiment: This movie was terrible" and the expected output would be "negative".
### Pretraining and Fine-Tuning:
Like BERT, RoBERTa, and other Transformer models, T5 is pretrained on a large corpus of text data and then fine-tuned on specific tasks. However, T5 uses a slightly different pretraining objective: the authors propose a denoising autoencoder objective where the model is trained to reconstruct the original text from a corrupted version of it.
During pretraining, the model is fed a corrupted version of the input text and is trained to recover the original uncorrupted text. This is done by randomly masking out spans of text from the input {as opposed to individual tokens, as in BERT}, and the model must predict the masked out spans based on the context provided by the unmasked text.
### Noteworthy Findings:
The paper also presents a number of noteworthy findings:
1. **Importance of task-specific prefix:** By providing a task description as a prefix to each input, the model is able to effectively switch between different tasks. This highlights the power of inductive biases in guiding the model's learning process.
2. **Benefits of unified text-to-text format:** The unified text-to-text format enables a simple and effective approach to multi-task learning, where the model is trained on multiple tasks simultaneously. This leads to improvements in performance on individual tasks.
3. **Effectiveness of the denoising objective:** The authors find that the denoising pretraining objective is effective in enabling the model to learn to generate coherent and contextually appropriate text.
4. **Effectiveness of large-scale pretraining:** The authors find that training larger models on more data for longer periods of time generally leads to better performance. This finding is consistent with similar observations made in other large-scale language model research such as BERT and GPT-2.
Despite these positive results, the T5 approach has its limitations. For example, the authors note that the model sometimes generates plausible-sounding but incorrect or nonsensical answers. This indicates that while the model has learned to generate fluent text, it may not fully understand the semantics of the input.
The implications of the T5 paper are significant. It introduces a powerful and flexible framework for transfer learning in NLP that can handle a wide range of tasks. It also contributes to our understanding of the factors that influence the effectiveness of transfer learning, including the importance of the pretraining objective, the scale of pretraining, and the use of task-specific prefixes.
The T5 approach has been widely adopted in the NLP community and has inspired further research into transfer learning and multi-task learning. However, as with all models, it's important to consider its limitations and the specific requirements of the task at hand when deciding whether to use it. For example, while T5 is very powerful, it may be overkill for simple tasks or tasks where the training data is very different from the pretraining data.
It's also worth noting that the computational resources required to train T5 are substantial. This could limit its accessibility for researchers and developers with limited resources, and highlights the ongoing challenge in the field of AI research of balancing performance with resource efficiency and accessibility.
Finally, as with all powerful AI models, it's important to consider the ethical implications of its use. For example, the ability of T5 to generate fluent text could be misused to produce misleading or harmful content. This underscores the importance of using such models responsibly and in a way that benefits society.
go to post
ALBERT: A Lite BERT for Self-supervised Learning of Language Representation
"ALBERT: A Lite BERT for Self-supervised Learning of Language Representations" is a paper by Zhenzhong Lan and others from Google Research. Published in 2019, the paper presents ALBERT, a new model architecture that is a lighter and more memory-efficient variant of BERT, a transformer-based model for NLP tasks.
ALBERT introduces two key changes to the BERT architecture to reduce the model size and increase training speed without compromising performance:
1. **Factorized embedding parameterization**: This is a method that separates the size of the hidden layers from the size of the vocabulary embeddings. This is done by using two separate matrices for the embedding layer: one for the token embeddings and one for the hidden layers. The token embeddings are projected to the dimension of the hidden layers through a linear transformation. This way, the model can have a large vocabulary of embeddings with a relatively small embedding size, and then project these embeddings into the larger dimension required by the hidden layers. The model parameters are thus factorized into two smaller matrices, reducing the total number of parameters.
2. **Cross-layer parameter sharing**: This is a technique that shares parameters across the multiple layers in the transformer. In BERT, each transformer layer has separate parameters, while in ALBERT, all layers share the same parameters. This reduces the model size and also the number of computations required during training. There are different ways to implement cross-layer parameter sharing, such as sharing all parameters, sharing feed-forward network parameters, or sharing attention parameters.
The structure of the ALBERT transformer layer is similar to that of the original Transformer model. Given the output of the layer \(l\) as \(H^l\), the output of the self-attention sub-layer as \(A^l\), and the output of the feed-forward network as \(F^l\), the output of each layer is computed as:
\[
H^l = \text{LayerNorm}(H^{l-1} + A^l)
\]
\[
F^l = \text{LayerNorm}(H^l + \text{FFN}(H^l))
\]
But remember that in ALBERT, the parameters for computing \(A^l\) and \(F^l\) are shared across all layers.
ALBERT uses the same training objectives as BERT: masked language modeling and next sentence prediction. However, the authors later introduced a sentence-order prediction task to replace the next sentence prediction task, as it was found to be more effective.
The main findings of the paper are that ALBERT performs comparably to much larger BERT models while being significantly smaller and faster to train. This is largely due to the two main architectural changes: factorized embedding parameterization and cross-layer parameter sharing.
The implications of the ALBERT paper are significant. It introduces a new approach to building transformer models that are more memory-efficient and faster to train, making them more accessible for researchers and developers with limited resources. It also contributes to our understanding of how to design effective architectures for large-scale language models. However, as with all models, it's important to consider the limitations and specific requirements of the task at hand when deciding whether to use ALBERT. For example, while ALBERT is very powerful, it may be overkill for simple tasks or tasks where the training data is very different from the pretraining data.
Additionally, while ALBERT reduces the model size, the computational resources required to train ALBERT are still substantial. This highlights the ongoing challenge in the field of AI research of balancing performance with resource efficiency and accessibility. Finally, as with all powerful AI models, it's important to consider the ethical implications of its use. For example, the ability of ALBERT to generate fluent text could be misused to produce misleading or harmful content. This underscores the importance of using such models responsibly and in a way that benefits society.
The ALBERT model has been widely adopted in the NLP community and has inspired further research into efficient model architectures and the use of parameter sharing in deep learning. This work demonstrates that it's possible to achieve high performance on NLP tasks with models that are significantly smaller and more efficient than previous state-of-the-art models. However, as with all AI research, it's important to continue pushing the boundaries of what's possible while also considering the broader implications of the technology.
# Architecture
The main innovation in ALBERT's model architecture is the factorization of the embedding matrix into two smaller matrices.
In the original BERT model, the token embeddings are of the same size as the hidden states. So, if we have a vocabulary size \(V\), a hidden size \(H\), and \(L\) layers, the size of the token embedding matrix is \(V \times H\). This means that the number of parameters in the embedding layer scales with the size of the hidden layers, which can be quite large.
In ALBERT, the authors propose to separate the size of the token embeddings from the size of the hidden layers. They introduce an additional projection layer that maps the token embeddings to the size of the hidden layers. So, instead of having a single \(V \times H\) matrix, they have a \(V \times E\) matrix for the token embeddings, and an \(E \times H\) matrix for the projection, where \(E\) is the embedding size and is typically much smaller than \(H\).
So, the token embeddings are first looked up in the \(V \times E\) matrix, resulting in a \(N \times E\) matrix for a sequence of \(N\) tokens. This is then projected to the \(H\)-dimensional space using the \(E \times H\) matrix, resulting in a \(N \times H\) matrix that can be fed into the transformer layers.
This factorization of the embedding matrix reduces the number of parameters and makes the model more efficient. The smaller \(E\) dimension also means that the model can handle a larger vocabulary without significantly increasing the number of parameters.
This architectural change is one of the key reasons why ALBERT is more parameter-efficient than BERT. The other main change in ALBERT is the use of cross-layer parameter sharing, which further reduces the number of parameters and increases training efficiency.
## If \(E\) is less than \(H\), and the projection is linear, how is any information being added?
That's a great question. When the embedding size \(E\) is less than the hidden size \(H\), and a linear projection is used to project the embeddings into the larger hidden space, no new information is technically added to the model. The projection is essentially stretching the \(E\)-dimensional embeddings into a \(H\)-dimensional space.
The purpose of this factorized embedding parameterization is not to add new information, but to reduce the number of parameters in the model. By having a smaller \(E\), the model can handle a larger vocabulary without significantly increasing the number of parameters. This makes the model more efficient and faster to train.
It's worth noting that while no new information is added by the projection, the higher-dimensional space may allow the model to learn more complex representations in the subsequent layers {at the cost of more paramters in the model from the \(E \times H\) matrix}. The transformer layers can potentially learn to use the additional dimensions to capture more complex patterns in the data.
However, it's also possible that some information could be lost or distorted during the projection, especially if \(H\) is much larger than \(E\). This is a trade-off that the designers of ALBERT chose to make in order to achieve a smaller and more efficient model. The impressive performance of ALBERT on a range of NLP tasks suggests that this trade-off was successful, but it's possible that for certain tasks or datasets, a different trade-off might be more effective.
go to post
Big Bird: Transformers for Longer Sequences
## TLDR
Instead of using attention on all tokens in an input sequence, for a token t in the input sequence, only attend to some local tokens, some special global tokens {looks like just the first few tokens in the sequence}, and some random tokens as well. This allows for very long input sequences.
## Introduction
The paper "Big Bird: Transformers for Longer Sequences" by Manzil Zaheer et al. was published by Google Research in 2020. It introduces a new transformer architecture called BigBird, which can handle much longer sequences than the typical transformer models such as BERT or GPT. This new architecture alleviates the quadratic dependency on input length in Transformer attention mechanisms, which has previously limited their ability to process long sequences.
## Motivation
Standard Transformers suffer from a quadratic complexity issue due to the full self-attention mechanism. Specifically, for a sequence of length \(n\), the self-attention mechanism computes a dot product between each pair of tokens in the sequence, leading to a complexity of \(O(n^2)\). This makes it computationally inefficient for longer sequences.
## BigBird Model
BigBird modifies the standard Transformer model by using a sparse attention mechanism. Instead of having each token attend to every other token in the sequence, each token in BigBird attends to a fixed number of tokens. This results in a significantly reduced complexity of \(O(n)\), making it feasible to process longer sequences.
The sparsity pattern of BigBird's attention mechanism is designed in such a way that it includes the following types of attention:
1. **Local Attention:** Each token attends to its neighboring tokens. This helps the model capture local dependencies in the sequence.
2. **Global Attention:** Each token also attends to a fixed set of global tokens that are common for all tokens. This helps the model capture important global context that is relevant to all tokens.
3. **Random Attention:** Each token attends to a set of random tokens. This helps the model capture long-range dependencies in the sequence that cannot be captured by local or global attention.
This pattern can be visualized as follows:

## Mathematical Formulation
The standard Transformer computes the self-attention as follows:
\[ A = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V \]
where \(Q\), \(K\), and \(V\) are the query, key, and value matrices, and \(d\) is the dimension of the query and key vectors.
In contrast, BigBird computes the self-attention as follows:
\[ A = \text{softmax}\left(\frac{QK_{\text{BB}}^T}{\sqrt{d}}\right)V_{\text{BB}} \]
where \(K_{\text{BB}}\) and \(V_{\text{BB}}\) are the key and value matrices for the BigBird attention pattern. They are computed by concatenating the key and value vectors for the local, global, and random tokens.
## Results
The authors of the paper tested BigBird on a variety of tasks and found that it outperformed other models on long-sequence tasks. They also found that it was competitive with other models on standard benchmark tasks, demonstrating its versatility.
## Implications
The BigBird model has significant implications for the field of natural language processing. It enables the processing of longer sequences, which can be beneficial for many applications such as document summarization, long-form question answering, and other tasks that require understanding of long sequences of text.
It also demonstrates that sparse attention mechanisms can be as effective as full self-attention mechanisms, which challenges the conventional wisdom in the field. This opens up new possibilities for designing more efficient Transformer models.
## How does the model choose which global tokens to attend to?
In the BigBird model, the global tokens are predefined and fixed throughout the sequence. They do not change dynamically based on the input sequence.
The authors of the BigBird paper propose to select the first few tokens of the sequence as the global tokens. The intuition behind this is that the beginning of the sequence often contains important information that should be attended to by all other tokens. For example, in a document, the title and introductory paragraph often summarize the main points of the entire document.
By having each token attend to these global tokens, the model can effectively propagate this important global context throughout the sequence. This allows each token to not only understand its local context, but also relate it to the global context of the sequence.
The number of global tokens is a hyperparameter that needs to be chosen based on the specific task and dataset. The authors found that having a small fraction of the sequence length as global tokens (e.g., 2-10%) worked well in their experiments.
go to post
Switch Transformers: Scaling to Trillion Parameter Models
"Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity" published by Google Research in 2021. The paper presents an approach to scaling up transformer models to the trillion-parameter scale with a method called "mixture of experts".
## Introduction
The "Switch Transformer" paper presents a new model architecture that uses a routing mechanism to dynamically route tokens to a subset of experts (sub-networks) in each layer of the model. By doing so, it achieves both computational efficiency and model capacity expansion. This approach allows the model to scale up to the trillion-parameter level, which is an order of magnitude larger than previous transformer models.
## Mixture of Experts (MoE)
The core idea behind the Switch Transformer is the "mixture of experts" (MoE) approach. In this approach, the model consists of multiple "expert" sub-networks, each of which specializes in processing a certain type of input.
At each layer, the model decides which expert to route each token to based on the input. This is done using a gating network, which computes a distribution over the experts for each token. The token is then routed to one or more experts based on this distribution.
The MoE approach allows the model to significantly increase its capacity without a corresponding increase in computation. This is because only a small subset of experts needs to be active for each token, allowing the model to scale up the number of experts without increasing the computation cost per token.
## Mathematical Formulation
The gating network in the MoE layer is formulated as follows:
\[
p_k(x) = \frac{\exp(g_k(x))}{\sum_{j=1}^K \exp(g_j(x))}
\]
where \(g_k(x)\) is the gating score for expert \(k\) computed by a feed-forward network, and \(K\) is the total number of experts. The model then selects the top \(L\) experts for each token based on these scores.
The output of the MoE layer is computed as a weighted sum of the outputs of the selected experts:
\[
y = \sum_{k=1}^K p_k(x) f_k(x)
\]
where \(f_k(x)\) is the output of expert \(k\).
## Routing Algorithm
To ensure that the computational cost does not grow with the number of experts, the model uses a novel routing algorithm that evenly distributes the tokens among the experts. This ensures that each expert processes approximately the same number of tokens, maximizing the utilization of the experts.
## Results
The authors of the paper tested the Switch Transformer on a variety of tasks and found that it outperformed other models in terms of both performance and efficiency. The model achieved state-of-the-art results on the One Billion Word benchmark and was competitive with other models on the WMT'14 English to French translation task. It also demonstrated superior performance on the multilingual translation task, outperforming other models by a large margin.
## Implications
The Switch Transformer model has significant implications for the field of natural language processing. It demonstrates that it is possible to scale up transformer models to the trillion-parameter level, which opens up new possibilities for tackling more complex tasks and larger datasets.
The model also demonstrates the power of the mixture of experts approach, which allows the model to increase its capacity without a corresponding increase in computation. This approach could be applied to other types of models and tasks, potentially leading to significant advancements in the field.
go to post
TurboTransformers: Optimizing the Speed and Memory of Transformer Models at
The paper "TurboTransformers: An Efficient GPU Serving System For Transformer Models" by Jiarui Fang, Yang Yu, Chengduo Zhao, and Jie Zhou presents a new system aimed at optimizing the speed and memory utilization of Transformer models, particularly when deployed on GPUs.
The authors start by acknowledging the significant role Transformers play in current NLP tasks. Transformers have an advantage over Recurrent Neural Network (RNN) models in that they can process all sequence lengths in parallel, leading to higher accuracy for long sequences.
However, they note that efficient deployment of Transformers for online services in data center environments equipped with GPUs can be challenging. This is primarily due to the increased computation introduced by Transformer structures, which makes it difficult to meet latency and throughput requirements. Furthermore, Transformer models require more memory, which increases the cost of deployment.
To address these issues, the authors propose TurboTransformers, a system designed to accelerate Transformer inference and reduce memory usage. The key techniques used in TurboTransformers include:
1. A layer-wise adaptive scheduler: The scheduler controls the execution order of different layers in the Transformer. The authors note that this scheduler can optimize the overlap of computation and data transfer, thereby improving the efficiency of execution.
2. FP16-INT8 mixed precision strategy: The authors propose a strategy that uses a mix of FP16 and INT8 precision during inference. This strategy can reduce memory usage and improve the speed of the inference without sacrificing the accuracy of the model.
3. Kernel fusion and specialization: The authors propose a technique for fusing several small kernels into one large kernel, as well as for specializing kernels for specific sizes. Both of these techniques can improve the speed of the inference.
4. Cache-friendly algorithm design: The authors propose an algorithm that can better utilize GPU cache, thereby further speeding up the inference.
The authors present an extensive experimental evaluation of TurboTransformers. They compare its performance against several other Transformer optimization systems, including TensorRT and TVM. The results show that TurboTransformers can achieve higher throughput and lower latency compared to these systems. The authors also show that TurboTransformers can reduce memory usage significantly compared to other systems.
In terms of implications, TurboTransformers can help in deploying Transformer models in real-world, resource-constrained environments, such as data centers. By reducing memory usage and improving speed, it can lower the cost and improve the efficiency of deploying these models. The techniques used in TurboTransformers can also be applied to other models and tasks, not just Transformers, which makes this work broadly applicable.
go to post
Visualizing and Understanding Convolutional Networks
"Visualizing and Understanding Convolutional Networks" was published in 2014. This paper is often recognized as a landmark work in interpreting convolutional neural networks (CNNs).
**Convolutional Neural Networks (CNNs)**
CNNs are a class of deep learning models, most commonly applied to analyzing visual imagery. They are designed to automatically and adaptively learn spatial hierarchies of features from the input data.
The architecture of a typical CNN consists of an input and an output layer, as well as multiple hidden layers in between. These hidden layers are often composed of convolutional layers, pooling layers, fully connected layers, and normalization layers.
**Deconvolutional Networks**
A key concept introduced in the paper is the use of deconvolutional networks to map feature activations back to the input pixel space, i.e., projecting the feature activations of a layer in a CNN back to the pixel space.
The deconvolutional network can be seen as a mirror image of the convolutional network it visualizes. For each convolutional layer in the CNN, there is a corresponding deconvolutional layer in the deconvnet. The layers in the deconvnet upsample, rectify, and filter their input to produce their output.
In mathematical terms, given a convolutional layer defined by
\[
f(x) = max(0, Wx + b)
\]
where \(x\) is the input, \(W\) is the weight matrix, and \(b\) is the bias vector, the corresponding deconvolutional layer is defined by
\[
g(y) = W^T max(0, y)
\]
where \(y\) is the input to the deconvolutional layer, and \(W^T\) is the transposed weight matrix from the corresponding convolutional layer.
**Feature Visualization**
The paper introduced a visualization technique that reveals the input stimuli that excite individual feature maps at any layer in the model. The authors used a deconvolutional network to project the feature activations back to the input pixel space.
The procedure for generating these visualizations can be summarized as follows:
1. Perform a forward pass through the network to compute the feature activations for each layer.
2. Choose a feature map at a layer of interest, and set all the other activations in this layer to zero.
3. Perform a backward pass through the deconvolutional network to project this feature map back to the input pixel space.
This process is performed separately for each feature map in each layer of interest, resulting in a set of images that show what features each map has learned to recognize.
**Layer-wise Visualization**
The authors also propose a way to visualize the features learned by each layer in the CNN.
For the first layer, which is directly connected to the pixel space, the learned features are simply the weights of the filters, which can be visualized as images.
For the higher layers, the authors proposed to find the nine image patches from the training set that cause the highest activation for each feature map. These patches were then projected back to the pixel space using the deconvolutional network, providing a visualization of what each feature map is looking for in the input images.
**Implications**
The techniques introduced in this paper have proven to be extremely valuable for understanding and debugging convolutional neural networks. They provide a way to visualize what features a CNN has learned to recognize
, which can help to explain why the network is making certain decisions, and where it might be going wrong. This can be particularly helpful for tasks where interpretability is important, such as medical imaging, where understanding the reasoning behind a model's prediction can be as important as the prediction itself.
In addition to providing a tool for understanding and interpreting CNNs, these visualization techniques also shed light on the hierarchical feature learning process that occurs within these networks. The visualizations clearly show how the network learns to recognize simple patterns and structures at the lower layers, and more complex, abstract features at the higher layers. This confirms some of the central hypotheses behind the design of convolutional networks, and provides a clearer picture of why these models are so effective for image recognition tasks.
It's also worth noting that this work has stimulated a great deal of subsequent research into interpretability and visualization of neural networks. Since this paper was published, numerous other techniques have been proposed for visualizing and interpreting CNNs, many of which build on the ideas introduced in this work.
Unfortunately, I cannot provide actual visualizations or graphics as part of this response. The general idea, however, is that the generated images highlight regions in the input that cause high activations for a particular feature map, effectively showing what that feature map is looking for in the input.
go to post
Explaining the Predictions of Any Classifier
The paper "Explaining the Predictions of Any Classifier" by Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin, introduced a model-agnostic explanation method named LIME (Local Interpretable Model-Agnostic Explanations). LIME is designed to explain the predictions of any classifier or regressor in a human-understandable manner.
## Overview of LIME
The main idea of LIME is to approximate the prediction of any classifier locally with an interpretable model. The interpretable model can be a linear model, decision tree, or anything that can be easily understood by humans.
Here are the key steps in the LIME algorithm:
1. **Sample Generation**: Given an instance for which we want to explain the prediction, LIME generates a set of perturbed samples. The generation of these samples is done by randomly turning some features on and off.
2. **Weight Assignment**: LIME assigns weights to these new samples based on their proximity to the original instance. Proximity is typically measured using some form of distance metric, such as cosine similarity in the case of text data or Euclidean distance for tabular data.
3. **Model Training**: LIME trains an interpretable model (e.g., linear regression, decision tree) on the dataset created in steps 1 and 2. The target variable for this regression model is the predictions of the original black-box model for the sampled instances.
4. **Explanation Generation**: The interpretable model's parameters are used to explain why the black-box model made the prediction it did on the instance of interest.
In mathematical terms, the LIME algorithm solves the following optimization problem:
\[
\xi = \arg\min_{g \in G} L(f, g, \pi_x) + \Omega(g)
\]
where:
- \(f\) is the black-box model,
- \(g\) is the interpretable model,
- \(G\) is the class of interpretable models,
- \(\pi_x\) is the proximity measure around instance \(x\),
- \(L\) is a loss function that measures how close the behavior of \(g\) is to \(f\) in the vicinity of \(x\), and
- \(\Omega(g)\) is a complexity measure of the interpretable model \(g\).
The first term \(L(f, g, \pi_x)\) encourages \(g\) to mimic \(f\) in the vicinity of \(x\), while the second term \(\Omega(g)\) discourages overly complex explanations. This is a classic bias-variance tradeoff.
## Implications
The LIME algorithm is model-agnostic, meaning it can be applied to any classifier or regressor. This makes it very versatile and useful in many different contexts. Its focus on local explanations also means that it can produce highly accurate explanations for individual predictions, even when the global behavior of the model is extremely complex and non-linear.
The interpretability provided by LIME can increase trust in machine learning models, help debug and improve models, and ensure that models are making decisions for the right reasons. It can also help meet legal requirements related to the "right to explanation", where users are allowed to know why a model made a certain decision about them.
However, it's important to remember that LIME's explanations are approximations and may not perfectly capture the true reasoning of the black-box model. The quality of the explanations also depends on the choice of interpretable model and the proximity measure.
LIME also has computational costs: it requires generating many perturbed samples and training a new interpretable model for each prediction that needs to be explained. This can be computationally expensive for large datasets or complex black-box models.
go to post
Man is to Programmer as Woman is to Homemaker? Debiasing Word Embeddings
## TLDR
Basically, obviously word embeddings learned on the internet {and moreover, just straight-up human content} are really sexist. You can improve things slightly by taking a word embedding you care about {e.g. computer programmer} and making it equidistant to the categories you care about {e.g. man, woman}.
## Introduction
The paper "Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings" by Bolukbasi et al., published in 2016, presented a novel approach to reduce gender bias in word embeddings. Word embeddings, such as Word2Vec or GloVe, are trained on large corpora of text data and often reflect societal biases present in the training data. For example, these models may associate certain professions more with one gender than another, perpetuating stereotypes.
The authors began by identifying the gender bias present in word embeddings. They proposed a methodology to quantify the bias and demonstrated that even state-of-the-art embeddings are not immune to such biases.
## Identifying and Quantifying Bias
The authors used the GloVe word embeddings trained on the Common Crawl corpus and showed that they can capture gender stereotypes to a large extent. They defined bias in terms of the "gender direction", a concept based on the vector space model representation of words.
Given a set of word pairs that exhibit true gender distinction (like 'he'-'she', 'his'-'hers', 'man'-'woman', etc.), they computed the differences of the corresponding word vectors and averaged these difference vectors to obtain the gender direction vector. More formally, the gender direction \( \vec{b} \) can be defined as:
\[
\vec{b} = \frac{1}{|S|}\sum_{(w_a, w_b) \in S} \frac{(\vec{w_a} - \vec{w_b})}{\| \vec{w_a} - \vec{w_b} \|}
\]
where \( S \) is the set of gender-specific word pairs, \( \vec{w_a} \) and \( \vec{w_b} \) are the vector representations of the words in a pair, and \( \| \cdot \| \) is the Euclidean norm.
The cosine similarity of a word \( w \) with the gender direction \( \vec{b} \) was used to measure the gender bias of that word. Words with high absolute similarity were considered to be gender-biased.
## Debiasing Word Embeddings
The authors proposed a two-step process for debiasing the word embeddings:
1. **Neutralize:** For each word they wanted to be gender-neutral, they made sure it was equidistant to a predefined set of gender-specific words by projecting it onto the space orthogonal to the gender direction. This ensures that the word is gender-neutral in the embedding space.
Formally, if \( \vec{w} \) is the vector of a gender-neutral word, then its debiased vector \( \vec{w_{\text{debiased}}} \) is given by:
\[
\vec{w_{\text{debiased}}} = \vec{w} - \vec{b} \cdot \langle \vec{w}, \vec{b} \rangle
\]
where \( \langle \cdot, \cdot \rangle \) is the dot product.
2. **Equalize pairs:** For every pair of words that should be equal apart from their gender (like 'grandmother'-'grandfather'), they moved the word vectors to be equidistant from the gender direction.
The equalization formula for a pair of words \( \vec{w_a} \) and \( \vec{w_b} \) is given by:
\[
\mu = \frac{\vec{w_a} + \vec{w_b}}{2}
\]
\[
\mu_B = \vec{b} \cdot \langle \mu, \vec{b} \rangle
\]
The equalization formula for a pair of words \( \vec{w_a} \) and \( \vec{w_b} \) continues as follows:
The orthogonal component of \(\mu\), denoted as \(\mu_{B}\), is given by:
\[
\mu_{B} = \mu - \mu_{B}
\]
The projections of \( \vec{w_a} \) and \( \vec{w_b} \) onto the gender direction are computed as:
\[
w_{aB} = \vec{b} \cdot \langle \vec{w_a}, \vec{b} \rangle
\]
\[
w_{bB} = \vec{b} \cdot \langle \vec{w_b}, \vec{b} \rangle
\]
The corrected projections \(w_{aB_{\text{corrected}}}\) and \(w_{bB_{\text{corrected}}}\) for \( \vec{w_a} \) and \( \vec{w_b} \) respectively are given by:
\[
w_{aB_{\text{corrected}}} = \sqrt{|\vec{w_a}|^2 - |\mu_{B}|^2} \cdot \frac{(w_{aB} - \mu_{B})}{|\vec{w_a} - \mu_{B} - \mu_{B}|}
\]
\[
w_{bB_{\text{corrected}}} = \sqrt{|\vec{w_b}|^2 - |\mu_{B}|^2} \cdot \frac{(w_{bB} - \mu_{B})}{|\vec{w_b} - \mu_{B} - \mu_{B}|}
\]
Finally, the debiased vectors \( \vec{w_{a_{\text{debiased}}}} \) and \( \vec{w_{b_{\text{debiased}}}} \) for \( \vec{w_a} \) and \( \vec{w_b} \) respectively are computed as:
\[
\vec{w_{a_{\text{debiased}}}} = \mu_{B} + w_{aB_{\text{corrected}}}
\]
\[
\vec{w_{b_{\text{debiased}}}} = \mu_{B} + w_{bB_{\text{corrected}}}
\]
## Implications and Critique
The paper was an important step towards acknowledging and addressing the problem of bias in AI, particularly in natural language processing. It presented a clear methodology for identifying and reducing gender bias in word embeddings, which can be extended to other forms of biases as well.
However, it's important to note that this method does not eliminate all forms of bias. It only reduces explicit bias in the geometric space of the word embeddings, and does not handle implicit, nuanced, or context-specific biases. The method also requires a predefined list of gender-neutral words, and its effectiveness depends on the completeness and accuracy of this list.
Moreover, while it's important to remove harmful biases from AI systems, there's an ongoing debate about whether "debiasing" can sometimes oversimplify the complexity of social phenomena and potentially erase important aspects of identity. Therefore, while this method can be a useful tool in some contexts, it's not a one-size-fits-all solution to the problem of bias in AI.
go to post
A Unified Approach to Interpreting Model Predictions {SHAP}
## TLDR
Similar to LIME, but instead of running permutations on features and analysing the resulting predictions, SHAP works off of feature sets. However, many types of ML models - like most neural networks, can't handle NULL data, i.e. incomplete feature sets. So you have to do some computationally intensive hacks to get around this. People seem to like it better than LIME, but that may just be because it's more confusing and nobody I've met seems to understand how it works. Which people love, of course. But hey, maybe it is better when it works, dunno!
## SHAP Overview
SHAP is a unified measure of feature importance that assigns each feature an importance value for a particular prediction. It's based on the concept of Shapley values from cooperative game theory. The key idea of Shapley values is to fairly distribute the "payout" {in this case, the prediction of the model} among the "players" {the features}, taking into account all possible coalitions {subsets of features}.
The Shapley value for a feature is calculated as the weighted sum of the marginal contributions of the feature to the prediction for all possible coalitions of features. The marginal contribution of a feature is the difference in the prediction when including the feature versus not including the feature, keeping all other features the same.
In formal terms, the Shapley value \(\phi_i\) for feature \(i\) is given by:
\[
\phi_i = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|!(|N|-|S|-1)!}{|N|!} \left[f(S \cup \{i\}) - f(S)\right]
\]
where:
- \(N\) is the set of all features,
- \(S\) is a subset of \(N\) that does not include feature \(i\),
- \(f(S)\) is the prediction of the model for feature set \(S\),
- \(|S|\) and \(|N|\) denote the cardinality of sets \(S\) and \(N\) respectively,
- \(|S|!\) and \(|N|!\) denote the factorial of the cardinalities.
The authors extended the concept of Shapley values to SHAP values, which have three desirable properties:
- **Local Accuracy**: The sum of the SHAP values for all features plus the base value (expected prediction) equals the prediction for the instance.
- **Missingness**: If a feature is "missing" in a coalition, it does not contribute to the prediction.
- **Consistency**: If a model changes so that it relies more on a feature, the attributed importance for that feature should not decrease.
## KernelSHAP and TreeSHAP
The paper also presents practical algorithms to compute SHAP values: KernelSHAP and TreeSHAP.
**KernelSHAP** is a model-agnostic method that uses a specially weighted local linear regression to estimate SHAP values. Given a prediction to explain, it samples instances, computes the similarities between the sampled instances and the instance of interest, and uses these similarities as weights in a linear regression. The coefficients of the linear regression are the estimated SHAP values.
**TreeSHAP** is a fast, exact method to compute SHAP values for tree-based models (e.g., decision trees, random forests, gradient boosting). It leverages the structure of tree-based models to compute SHAP values efficiently.
## Implications
The SHAP method provides a unified, theoretically grounded approach to interpret the predictions of machine learning models. It has been widely adopted in various fields due to its ability to provide reliable and interpretable insights into complex models.
While SHAP greatly aids interpretability, it should be noted that it can be computationally expensive, particularly for high-dimensional data. Moreover, although SHAP provides a measure of feature importance, it does not directly provide insights into the interactions between features.
Finally, the interpretations given by SHAP are inherently local, which means they apply to individual predictions. While
these interpretations can be aggregated to understand global behavior, care must be taken to ensure these aggregations are meaningful and do not overlook important local behaviors.
The authors have also developed a Python library named `shap` that implements these methods, making them accessible to the broader data science community. The `shap` library includes functionality for visualizing SHAP values, which can help to communicate interpretations more effectively.
go to post
Understanding deep learning requires rethinking generalization
## TLDR
Neural networks are really good at memorizing random labels. And yet, even when they do so, they can still generalize pretty well. Additionally, common regularization methods aren't even neccessary for this generalization. This goes against standard bias-variance tradeoff and overfitting narratives, indicating we don't have a great understanding of how and why neural networks perform and generalize so well.
## Key Insights
The authors demonstrated that standard deep learning models can easily fit random labels. This is counter-intuitive because it suggests that these models have enough capacity to memorize even completely random data. This goes against the traditional understanding of overfitting, where a model with high capacity might overfit to the training data and perform poorly on unseen data.
They also showed that explicit regularization methods {like weight decay, dropout, data augmentation, etc.} are not necessary for these models to generalize well, again contradicting conventional wisdom. While these regularization methods can improve model performance, the models still generalized well without them.
In addition, they observed that deep learning models can fit the training data perfectly, achieving zero training error, but still perform well on the test data. This goes against the bias-variance trade-off concept, which posits that a model that fits the training data too well {i.e., a model with high variance} would perform poorly on unseen data.
## Experiments
To demonstrate these points, the authors conducted a series of experiments with deep learning models trained on the CIFAR-10 dataset. In one set of experiments, they replaced the true labels with random labels and showed that the models could fit these random labels perfectly. In another set of experiments, they trained the models without any regularization and found that they still generalized well.
## Implications
The authors argued that these observations suggest that the traditional statistical learning theory does not fully explain why deep learning models generalize well. They proposed that other factors, such as the optimization algorithm and the structure of the model architecture, might play important roles in the generalization of deep learning models. For example, the stochastic gradient descent {SGD} optimization algorithm, which is commonly used to train deep learning models, has an implicit regularization effect.
However, the authors did not provide a definitive explanation for their observations. They suggested that understanding deep learning requires rethinking generalization and proposed that more research is needed to develop new theories and frameworks that can explain the generalization behavior of deep learning models.
In conclusion, the paper challenged the conventional understanding of overfitting and generalization in deep learning and suggested that new theories are needed to explain why these models generalize well. The work has stimulated a lot of subsequent research into the theory of deep learning, aiming to bridge the gap between the empirical success of deep learning and our theoretical understanding of it.
go to post
The (Un)reliability of saliency methods
"The (Un)reliability of saliency methods" by Julius Adebayo et al. is a critical study that challenges the reliability of feature attribution methods, specifically saliency maps, in the interpretation of deep learning models. Specifically, if you do feature transformations, a lot of these tests' outputs change dramatically (predictably), which ain't great ya'll.
## Context
Saliency methods, also known as feature attribution methods, aim to explain the predictions of complex models, like neural networks, by attributing the prediction output to the input features. They produce a "saliency map" that highlights the important regions or features in the input that the model relies on to make a particular prediction.
There are several popular saliency methods, including:
1. **Vanilla Gradients:** This method simply computes the gradient of the output prediction with respect to the input features. The idea is that the magnitude of the gradient for a feature indicates how much a small change in that feature would affect the prediction. *Note: this can be a bit sensitive, particularly if features aren't normalized*
2. **GradientInput:** This method also computes the gradient of the output prediction with respect to the input features, but it multiplies the gradients by the input feature values. The intuition is that a feature is important if both its value and its gradient are high. *Note: of course, this only makes sense for some features. e.g. if features are all N(-1, 1) normalized then maybe using the absolute value makes sense, if there is no normalization then this may be a bit of a dumb approach. I could also see dividing by something like a feature value's paired p-value, i.e. the chance that a feature value in the dataset would be more extreme (in the tails) that the value when dealing with non-normalized features. Alternatively, maybe this is purely just being used to scale the df/dp partial derivative, which is going to be larger the smaller the distribution of the feature, generally speaking.*
3. **Guided Backpropagation:** This method modifies the standard backpropagation algorithm to only propagate positive gradients, effectively ignoring the features that would decrease the output prediction. The resulting saliency map highlights the features that would increase the prediction if they were increased. *Note: uhh. Yeah I mean there are a lot of problems with this but okay.*
4. **Integrated Gradients:** This method apparently computes the gradients not just at the given input, but at many points along the path from a baseline input {usually the zero input} to the given input, and then integrates these gradients. This method satisfies several desirable properties, such as sensitivity and implementation invariance. *Note: I don't understand why this would be a good approach yet, I think I'm missing the point. Also defining 'baseline input' seems hard. Avg features {bad for reasons}, zero features {very bad for reasons}, etc?*
5. **SmoothGrad:** This method adds noise to the input and averages the saliency maps over these noisy inputs. The idea is to reduce the noise in the saliency map and highlight the consistent features. *Note: ok yeah that makes sense. Computationally a lil intensive but usually with interpretability that's okay.*
These methods all aim to identify the important features in the input, but they can sometimes produce very different saliency maps for the same input, leading to different interpretations of the model's behavior. This inconsistency has motivated research into the reliability and robustness of these methods, such as the paper "The (Un)reliability of saliency methods" by Julius Adebayo et al.
## Key Insights
From the abstract: "In order to guarantee reliability, we posit that methods should fulfill input invariance, the requirement that a saliency method mirror the sensitivity of the model
with respect to transformations of the input. We show, through several examples,
that saliency methods that do not satisfy input invariance result in misleading attribution."
go to post
Interpretability Beyond Feature Attribution {TCAV}
## TLDR
Okay, so the basic approach is to define some high-level concept, such as 'stripes' in an image classification task or 'gender' in an NLP task. I think the basic idea is that given features that you {as a human expert, or whatnot} has determined represents some high-level concept, you record the resulting feature activations from one {or presumably more} hidden layer{s} in the network. Similarly, you record feature activations from input features that does *not* represent the concept. Maybe this is done over a variety of related feature inputs. Then, when predicting on some actual set of input features (like a picture of a Zebra or a prompt), you basically just do a frequentist (rejecting null hypothesis) statistical test to see if the feature activations where especially similar to e.g. 'stripes' when processing the image of a Zebra.
This seems fine and useful in some circumstances, but also defining the features and not-features for a high-level concept can be fairly ambiguous and tricky, and not rejecting the null hypothesis isn't really superb evidence that the concept isn't related to the output (as feature activations can change depending on the context of other input features, and you might be defining your input features poorly, etc).
## Background and Problem Statement
One of the main issues with neural networks is their "black box" nature. While they perform incredibly well on a wide variety of tasks, it is often challenging to understand the reasons behind their decisions. This lack of interpretability can be problematic in fields where transparency is crucial, such as healthcare or law.
The authors propose a new method to interpret the output of a neural network called Testing with Concept Activation Vectors {TCAV}. This approach provides a way to understand the influence of high-level concepts, such as "stripes" in an image classification task or "gender" in a language processing task, on the decisions made by the model. But at least it can be useful for identifying problem areas (e.g. gender bias).
## Concept Activation Vectors {CAVs}
The key idea in TCAV is the Concept Activation Vector {CAV}. A CAV for a concept (C) is a vector in the activation space of a hidden layer in the network. To obtain a CAV, we first need to collect a set of examples that represent the concept, and a set that does not. For instance, if our concept is "striped", we might gather a collection of images of striped and non-striped objects.
The activations from these two sets are then used to train a binary classifier, such as a linear classifier, where the positive class corresponds to the concept and the negative class to the non-concept. The decision boundary of this classifier, in the high-dimensional space of the layer activations, represents the CAV.
Mathematically, if \( A^+ \) and \( A^- \) are the sets of activations for the concept and non-concept examples respectively, and \( w \) is the weight vector of the trained linear classifier, then the CAV is given by the vector \( w \).
## Quantitative Testing with CAVs
Once the CAVs have been computed, they are used to interpret the decisions of the neural network. The authors propose a statistical test to determine whether the influence of a concept on the network's output is statistically significant.
Given an input \( x \) to the network and a concept C, we first compute the activations \( A \) of a hidden layer for the input. We then project these activations onto the CAV associated with the concept. The resulting scalar is called the TCAV score and measures the alignment of the input with the concept.
The TCAV score for a concept C, an input \( x \), and a hidden layer \( l \) is given by:
\[ TCAV_{C,l}(x) = \frac{A_l(x) \cdot CAV_C}{||A_l(x)|| ||CAV_C||} \]
The TCAV score is then used to perform a directional derivative test. The null hypothesis is that the TCAV score is not significantly different from 0. If the p-value is less than a predetermined threshold, then the null hypothesis is rejected, and we conclude that the concept has a significant impact on the network's decision.
## Results and Discussion
The authors applied the TCAV method to different tasks including image classification and sentence sentiment analysis. The results demonstrated that TCAV can provide meaningful interpretations of the decisions made by the neural networks.
For instance, in the image classification task, the authors showed that the concept of
"stripes" influenced the classification of images as "zebra". They found that the TCAV score for the "stripes" concept was significantly different from zero, indicating that the presence of stripes was an important factor in the classification decision.
In the sentence sentiment analysis task, they found that the gender of the subject in the sentence significantly influenced the sentiment score assigned by the network. This type of bias, which might be unintentional, can be identified using TCAV.
This paper is important as it provides a methodology to interpret the decisions made by complex neural networks in terms of understandable concepts. This not only helps to understand the decision-making process but can also uncover potential biases in the model's decisions. The TCAV method can be applied to any type of neural network and does not require any modifications to the network's architecture or training procedure.
Furthermore, the TCAV method provides a quantitative measure of the influence of a concept, which can be used for statistical hypothesis testing. This allows for rigorous statistical analysis of the interpretability of a neural network.
go to post
Sanity Checks for Saliency Maps
## TLDR
Yet again, common saliency (feature importance) methods are found to kind of suck. Specifically, this time it's shown that if you randomize model parameters or data, some of the saliency methods output pretty similar things, which ain't good. This is more evidence relating to the 2017 "The (Un)reliability of saliency methods" paper's {which showed that lots of saliency methods have really different outputs when you run transformations on the input data} theme, which is basically that a lot of our saliency methods are finicky and bad.
## Background and Problem Statement
The study of interpretability in deep learning, especially in the context of image classification tasks, often leverages saliency maps. These maps are used to highlight regions in an input image that a model deems important for making a particular classification. However, the reliability of these maps had been largely unquestioned until this work.
The authors in this paper raise concerns about the validity of conclusions drawn from saliency maps. They argue that saliency methods should be subjected to "sanity checks" to ensure they are providing meaningful insights about the model and data.
## Saliency Methods and Sanity Checks
Adebayo et al. focus on saliency methods that explain a classifier's prediction by assigning importance scores to input features, specifically targeting methods that compute the gradient of the output with respect to the input, such as Gradient*Input, Integrated Gradients, and SmoothGrad.
The authors propose two sanity checks for these saliency methods:
1. **Model Parameter Randomization Test:** In this test, the parameters of the model are randomly shuffled or re-initialized, destroying any learned information. If a saliency method is meaningful, the resulting saliency maps should change significantly after parameter randomization. If they don't change, it indicates that the saliency map might not be tied to the learned parameters and thus may not provide useful model interpretation.
2. **Data Randomization Test:** This test randomizes the labels in the training data, disrupting the correlation between the features and labels. After retraining on this randomized data, a meaningful saliency method should produce different saliency maps compared to the original model.
## Results and Discussion
Adebayo et al. apply these sanity checks to several popular saliency methods and find that many of them fail one or both tests. Specifically, they find that some saliency methods produce almost identical saliency maps even after the model parameters are randomized or the model is trained on randomized data. This result calls into question the validity of these methods as interpretability tools.
The authors suggest that the failure of these sanity checks by some saliency methods could be due to the high sensitivity of these methods to the input data, rather than the learned model parameters. This implies that these methods may be reflecting some inherent structure or pattern in the input data rather than providing insight into the model's decision-making process.
This paper has significant implications for the field of interpretability in deep learning. It highlights the importance of validating interpretability methods and provides a straightforward methodology for doing so. It suggests that researchers and practitioners should be cautious when drawing conclusions from saliency maps, and emphasizes the need for more reliable and validated methods for interpreting deep learning models.
go to post
Adam: A Method for Stochastic Optimization
## TLDR:
As we know, the learning rate is a hugely impactful parameter when training neural networks. Instead of having a flat learning rate over the entire course of training, the ADAM optimization algorithm is an adaptation of stochastic gradient descent {SGD} that modifies the learning rates used for each parameter over the course of training based on the moving average of the gradient - $dLoss/dp$ - and the moving average of the squared gradient - $dLoss^2/dp$. The basic idea behind this is that if your parameter {gradient} keeps on going in the same direction, you can expect that it will keep going in the same direction, and it'd be useful to increase your learning rate to get there fast. Alternatively, if your gradient is sort of bouncing around, then you probably want a smaller learning rate so you can settle into a more delicately optimized paramter value. ADAM didn't actually introduce this concept {often referred to as momentum}, but was novel for using parameter-specific adaptive learning rates in combination with these moving averages of gradients and squared gradients.
ADAM tends to perform very well in practice and is quite popular. Because of the adaptive learning rates, it tends to require less learning rate tuning and tends to converge faster than traditional SGD. It also, I believe, can be combined effectively with other optimization approaches, like learning-rate schedulers {e.g. one-cycle-policy}. Usually, the weight given to the moving averages is set to about 0.9 for the average gradient and 0.999 for the average squared gradient - i.e. the latter relies most heavily on the moving average, because squared values can be very bouncy and have high variance.
## Summary
"Adam: A Method for Stochastic Optimization" is a seminal paper that introduces the Adam optimization algorithm, an efficient method for adapting learning rates for each parameter in a neural network model. The key difference between Adam and earlier first-order gradient-based optimization methods, like stochastic gradient descent {SGD}, is that Adam computes adaptive learning rates for different parameters using estimates of first and second moments of the gradients, while SGD uses a fixed learning rate for all parameters.
In more detail, the Adam algorithm calculates an exponential moving average of the gradient and the squared gradient, and these moving averages are then used to scale the learning rate for each weight in the neural network. The moving averages themselves are estimates of the first moment {the mean: $ \frac{1}{n}\sum_{i=1}^{n} x_i$} and the second raw moment {the uncentered variance: $\frac{1}{n}\sum_{i=1}^{n} x_i^2$} of the gradient.
The algorithm is defined as follows:
1. Initialize the first and second moment vectors, \(m\) and \(v\), to 0.
2. For each iteration \(t\):
a. Obtain the gradients \(g_t\) on the current mini-batch.
b. Update biased first moment estimate: \(m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t\).
c. Update biased second raw moment estimate: \(v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2\).
d. Compute bias-corrected first moment estimate: \(\hat{m}_t = m_t / (1 - \beta_1^t)\).
e. Compute bias-corrected second raw moment estimate: \(\hat{v}_t = v_t / (1 - \beta_2^t)\).
f. Update parameters: \( \theta_{t+1} = \theta_t - \alpha \hat{m}_t / (\sqrt{\hat{v}_t} + \epsilon)\).
Here, \(\beta_1\) and \(\beta_2\) are the decay rates for the moving averages {typically set to 0.9 and 0.999, respectively}, \(\alpha\) is the step size or learning rate {typically set to 0.001}, and \(\epsilon\) is a small constant added for numerical stability {typically set to \(10^{-8}\)}.
One of the major advantages of Adam over traditional SGD is that it requires less tuning of the learning rate and converges faster in practice. It is also invariant to diagonal rescaling of the gradients, which makes it well-suited for problems with sparse gradients or with noisy and/or sparse updates.
go to post
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
## TLDR
Basically, this is a super popular and effective method to improve neural network regularization and generalization. You zero-out neuron outputs during training with probability $p$, which forces the network to not over-rely on specific neurons, and learn important feature representations multiple times (in slightly different ways, neccessarily). In theory and in practice this tends to prevent overfitting, which improves generalization. Later research has shown that approaches like dropout are not neccessary to achieve suprisingly good generalization from neural networks, but regardless it is still a very useful approach that is very commonly used.
During testing, dropout is not used. *NOTE: I have tested using dropout during testing to get a distribution of output predictions as a method of approximating model uncertainty. There are various issues with this and it only gets at a specific type of model uncertainty, but can still be quite useful and is quite easy to implment.*
## Summary
"Dropout: A Simple Way to Prevent Neural Networks from Overfitting" is a groundbreaking paper by Hinton et al. that introduced the concept of "dropout" as a simple and effective regularization technique to prevent overfitting in neural networks.
The dropout technique involves randomly "dropping out", or zeroing, a number of neuron outputs {output features} of the hidden layers in a neural network during training {or you can apply this to your initial input features in a non-hidden layer, too!). This means that each neuron output {'hidden unit' in the paper) is set to zero with a probability of \(p\), and it's kept with a probability of \(1-p\). This introduces noise into the output values of a layer, which can be thought of as creating a "thinned" network. Each unique dropout configuration corresponds to a different thinned network, and all these networks share weights. During training, dropout samples from this exponential set of different thinned architectures.
In more detail, if \(y\) is the vector of computed outputs of the dropout layer, and \(r\) is a vector of independent Bernoulli random variables each of which has probability \(p\) of being 1, then the operation of a dropout layer during training can be described by:
\[
r_j \sim Bernoulli(p)
\]
\[
\tilde{y} = r \odot y
\]
where \(\odot\) denotes element-wise multiplication.
During testing, no units are dropped out, but instead the layer's outputs are scaled down by a factor equal to the dropout rate, to balance the fact that more units are active than at training time. This can be seen as creating an ensemble of all subnetworks, and this ensemble method helps to reduce overfitting.
The dropout method provides a computationally cheap and remarkably effective regularization method to combine the predictions of many different models in order to improve generalization. The paper shows that dropout improves the performance of neural networks on supervised learning tasks in speech recognition, document classification, and several visual object recognition tasks. It's now a standard technique for training neural networks, especially deep neural networks.
## Details
The key idea behind dropout is to introduce randomness in the hidden layers of the network during training, which helps to prevent overfitting. By randomly dropping out neurons, we are essentially creating a new network at each training step. This is akin to training multiple separate neural networks with different architectures in parallel.
The training process with dropout can be summarized as follows:
1. A hidden unit is selected at random at each training step and its contribution to the network's learning at that step is temporarily removed.
2. The learning algorithm runs as usual and backpropagates the error terms and updates the weights.
3. At the next training step, a different set of hidden units is dropped out.
The randomness introduced by dropout forces the hidden layer to learn more robust features that are useful in conjunction with many different random subsets of the other neurons.
During testing or evaluation, the dropout procedure is not applied and the full network is used. However, the output of each neuron is multiplied by the dropout rate \(p\) to compensate for the fact that during training, on average, only \(p\) fraction of the neurons were active.
The use of dropout has been found to significantly improve the performance of deep neural networks, especially those suffering from overfitting due to having a large number of parameters. It is now a commonly used technique in deep learning model training.
In terms of mathematical representation, if we denote the output from a dropout layer during training as \(\tilde{y} = r \odot y\), where \(r\) is a vector of independent Bernoulli random variables each with probability \(p\) of being 1, then the output from the same layer during testing would be \(y' = p \cdot y\), which scales down the outputs by the dropout rate \(p\).
Dropout can be used along with other regularization techniques such as weight decay and max-norm constraints. It can also be combined with other optimization methods and learning rate schedules. The paper suggests that using dropout prevents network units from co-adapting too much to the data, thus improving the network's ability to generalize to unseen data.
## Later Work
Since the original Dropout was proposed, several variations have been developed to improve or alter the original mechanism. Here are a few examples:
1. **Spatial Dropout:** This is a variant of dropout that is designed for convolutional neural networks. In standard dropout, neurons are dropped randomly and independently. In contrast, spatial dropout drops entire 1D feature maps from the 3D inputs. The idea is that this would help the model to generalize better and reduce the overfitting by ensuring that the model learns to use all features rather than relying too much on a specific one.
2. **DropConnect:** This is another variant of dropout where instead of deactivating the neurons, it drops the connections between neurons. In other words, it sets weights within the network to zero with a certain probability during the training process.
3. **Variational Dropout:** This variant extends dropout into a Bayesian framework, where dropout is used as a variational inference technique to approximate the posterior distribution of the weights. Variational dropout can automatically adapt the dropout rates and can also be applied to recurrent architectures. *NOTE: imo most forms of bayesian neural networks - where weights have prior distributions - are kind of dumb, and are not doing what you might think they're doing when you hear 'bayesian neural network'. Not sure exactly how this approach would work, but - as a Bayesian - I usually don't bother with bayesian neural networks.*
4. **Alpha Dropout:** This variant of dropout is developed for Self-Normalizing Neural Networks (SNNs). It preserves the self-normalizing property where the mean and variance of the inputs are preserved allowing the SNN to self-normalize.
5. **DropBlock:** This variant is designed for convolutional neural networks. DropBlock extends the idea of spatial dropout by dropping contiguous regions of a feature map (blocks) instead of dropping out individual elements independently.
Each of these methods has different effects and can be better suited to some types of tasks or network architectures than others. The choice of which to use would typically be based on the specifics of the task and the network architecture in use.
go to post
Recommendation Algorithms
## TLDR
In practice, my guess is most modern approaches at companies with a lot of users use a neural-network based hybrid approach. That is, predict engagement with an item {where this is defined over multiple engagement types, e.g. likes / shares / saves / follow creator / favorite creator / purchases / what-have-you, perhaps with auxiliary losses as well to help learning} based on hybrid information: things like past user interactions {maybe a big embedding}, video information {likely a big embedding}, and device and account settings {maybe a smaller embedding}.
When it comes to neural-network based approaches, it seems like this could be defined as just a box-standard feed-forward prediction DNN where new data is periodically (e.g. data} fed back into the model to fine-tune & aid accuracy. Or you could potentially frame it as a reinforcement learning algorithm, too. Not sure how popular each of these approaches are.
A feed-forward net is simpler, but *may* have a harder time processing a the sequential nature of a user's behavior {particularly depending how the features are structured}. Like, you could weight more recent video statistics and embeddings higher, or add a time dimension to these features, but you'd have to build that into the features themselves.
Alternatively, RL-based recommender systems have, it sounds like, been increasingly used due to their ability to handle sequential decision making and focus on *long-term* rewards and engagement.
In an RL-based recommender system, the model {or "agent"} learns to make recommendations {or "actions"} that maximize some long-term reward signal, such as cumulative user engagement over time. The agent learns from feedback {or "rewards"} it receives after making recommendations, and it updates its strategy {or "policy"} based on this feedback.
RL-based recommender systems have the potential to outperform traditional methods in situations where long-term user engagement is important. For example, an RL agent could learn to recommend a diverse set of items to keep users interested in the long run, even if these items might not be the ones with the highest predicted engagement in the short term.
However, RL also comes with its own set of challenges, such as the difficulty of defining a suitable reward function, the need for exploration vs. exploitation, and the complexity of training RL models.
## Background Context
Historically, it seems like recommendation algorithms have fallen into these categories:
1. **Collaborative Filtering (CF)**: This approach makes recommendations based on patterns of user behavior. Collaborative filtering can be further divided into two sub-categories:
- **User-based Collaborative Filtering (User-User CF)**: This method finds users similar to the target user based on their rating history. The idea is that if two users agree on one issue, they are likely to agree on others as well. The similarity between users can be calculated using methods like Pearson correlation or cosine similarity. Once similar users are found, the ratings they've given to other items can be used to recommend items to the target user.
- **Item-based Collaborative Filtering (Item-Item CF)**: This method, on the other hand, calculates the similarity between items based on the ratings they've received from users. If two items are often rated similarly by users, then they are considered to be similar. Once similar items are found, they can be recommended to users who have rated one of the items in the pair.
2. **Content-Based Filtering (CBF)**: This approach makes recommendations based on the characteristics of items. For example, if a user has positively rated several action movies in the past, a content-based recommender might suggest more action movies for them to watch. This requires having some sort of descriptive profile for each item in the dataset, which could be based on manually assigned tags, machine learning algorithms that analyze text descriptions, or other methods.
3. **Hybrid Methods**: As the name suggests, hybrid methods combine collaborative and content-based filtering in various ways to make recommendations. The idea here is that by combining the strengths of both methods, you can achieve better performance than with either method alone. One simple way to create a hybrid recommender is to generate recommendations with both a CF and a CBF algorithm, then combine the results in some way, such as by taking a weighted average.
go to post
Factorization Machines
## TLDR
OK, so this is an old paper, but it was pretty impactful at the time, even if it's less relevant now. Basically, instead of just using a linear regression on basic features, this paper used a linear regression on features plus pairwise interactions between feature variables. This helped deal with the very sparse data common in recommendation algorithm problems, where the number of possible user-item interactions is typically much larger than the number of training samples. And since everything {I believe} is still essentially just a linear regression {with feature special sauce}, it's extremely computationally efficient {linear time}.
Cool stuff, although in modern-day times, this approach is probably very rarely used, at least when you have a lot of data and can throw a neural network at the problem instead.
## Summary
This paper introduced a new {at the time, 2010!} model called Factorization Machines {FM} designed to effectively handle data sparsity, a common problem in many recommendation systems.
Factorization Machines are a generic approach that allows you to mimic most factorization models by feature engineering. This is a significant advantage over standard factorization models, which are usually bound to specific problem definitions and thus do not allow for the incorporation of additional side information {e.g., user demographics in a movie recommendation system}.
The model architecture of FM is defined by the equation:
\[
\hat{y}(\mathbf{x}) = w_0 + \sum_{i=1}^{n} w_i x_i + \sum_{i=1}^{n} \sum_{j=i+1}^{n} \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j
\]
where:
- \(\hat{y}(\mathbf{x})\) is the predicted target variable.
- \(w_0\) is the global bias.
- \(w_i\) are the weights of the model.
- \(\mathbf{x}\) is the feature vector.
- \(\mathbf{v}_i\) and \(\mathbf{v}_j\) are latent vectors that capture interactions between pairs of variables.
- \(\langle \mathbf{v}_i, \mathbf{v}_j \rangle\) is the dot product of these latent vectors.
The first two terms on the right side of the equation represent a linear regression model. The third term captures pairwise interactions between variables, with each interaction being weighted by the dot product of the corresponding latent vectors. This term is what distinguishes FM from a standard linear model and enables it to effectively handle high-dimensional sparse data.
The model parameters {i.e., the weights and latent vectors} can be learned using any standard optimization algorithm, such as stochastic gradient descent or alternating least squares.
The main advantage of Factorization Machines is their ability to model interactions between features even in problems with very sparse data. This makes them particularly useful in recommendation systems, where the number of possible user-item interactions is typically much larger than the number of observed interactions.
Another advantage of FM is their computational efficiency. The model can be calculated in linear time with respect to the number of non-zero elements in the input data, which makes it feasible to use even on very large datasets.
The paper also demonstrates the effectiveness of FM through a series of experiments on real-world datasets. The results show that FM outperforms other factorization models in terms of prediction accuracy, especially in cases with very sparse data.
This work has significant implications for the field of recommendation systems and more generally for any problem involving high-dimensional sparse data. By providing a flexible and efficient way to model feature interactions, Factorization Machines offer a powerful tool for predictive modeling in these settings.
go to post
AutoRec: Autoencoders Meet Collaborative Filtering
## TLDR
Basic idea was to use an auto-encoder architecture to learn a very compressed embedding for your very sparse user-engagement data. A nice side-effect of this is that the 'errors' in your reconstructed feature vector can be used as predictions for what a user will want to engage with. Kind of a clever use, although probably not the most popular approach used today.
## Summary
This paper introduced AutoRec, a novel approach to collaborative filtering based on autoencoder architecture. Autoencoders are a type of neural network used for learning efficient codings of input data. They work by encoding the input into a compressed representation, then decoding this representation to reconstruct the original input. The authors of the paper apply this idea to collaborative filtering, using the autoencoder to learn a compressed representation of a user's interaction with items, and then using this representation to reconstruct the user's rating vector.
In AutoRec, each user is represented by a vector of their item ratings, with missing ratings filled in with zeros. This rating vector is passed through an autoencoder, which first encodes it into a hidden representation, and then decodes this representation to reconstruct the rating vector.
The encoding and decoding functions are defined as follows:
\[
f(x) = s(Wx + b)
\]
\[
g(z) = W'z + b'
\]
where:
- \(x\) is the input rating vector,
- \(W\) and \(b\) are the weight matrix and bias vector for the encoding function,
- \(s\) is a non-linear activation function, such as sigmoid or ReLU,
- \(z = f(x)\) is the encoded hidden representation,
- \(W'\) and \(b'\) are the weight matrix and bias vector for the decoding function.
The reconstructed rating vector \(g(f(x))\) is compared with the original rating vector \(x\) to calculate a reconstruction loss, which is then minimized using stochastic gradient descent or another optimization algorithm.
The key innovation in AutoRec is the use of the autoencoder architecture to perform collaborative filtering. By learning a compressed representation of each user's item interactions, AutoRec can effectively capture the underlying structure in the user-item interaction data, which allows it to make accurate rating predictions even for items that a user has not interacted with before.
The authors demonstrate the effectiveness of AutoRec through a series of experiments on real-world datasets, showing that it outperforms traditional collaborative filtering methods in terms of prediction accuracy.
The implications of this work are significant for the field of recommendation systems. By demonstrating that autoencoders can be effectively used for collaborative filtering, the authors open up a new avenue for research in this area. This could lead to the development of more advanced recommender systems that make better use of the rich structure in user-item interaction data.
In terms of practical applications, AutoRec could be used to build recommender systems for a wide range of domains, from e-commerce to content recommendation in social media platforms. By providing more accurate and personalized recommendations, these systems could significantly enhance user experience and engagement.
go to post
Field-aware Factorization Machines for CTR Prediction
## TLDR
Just a simple extension of the 2010 Factorization Machines paper, where essentially instead of just modeling pairwise feature interactions, you model pairwise feature interactions for each 'field', or feature categories. Same idea though, basically just a linear regression with some feature special-sauce baked in. Basically while before you only had one latent vector $v_i$ for each feature $x_i$ before, you have multiple latent vectors. Then when modeling interactions between $x_i$ and $x_j$, the model uses the latent vector $x_i,f$ that is associated with $x_j$'s field $f$ feature category. So, just a slightly more flexible {w/ more parameters} approach that can model different feature interactions based on the category of features interacting.
Still probably not used much today when there's big data involved.
## Summary
Field-aware Factorization Machines {FFMs} are an extension of Factorization Machines {FMs}, designed specifically to handle categorical data, which is common in many real-world applications such as click-through rate {CTR} prediction.
In traditional FMs, a feature interaction is modeled by the dot product of two latent vectors corresponding to the two features. However, in FFMs, each feature has multiple latent vectors, and the specific vector used to model an interaction depends on the "field" of the other feature in the interaction.
A field can be thought of as a high-level category that a feature belongs to. For example, in a movie recommendation system, movie ID, movie genre, and director might be different fields.
The FFM model is defined by the equation:
\[
\hat{y}(\mathbf{x}) = w_0 + \sum_{i=1}^{n} w_i x_i + \sum_{i=1}^{n} \sum_{j=i+1}^{n} \langle \mathbf{v}_{i,f_j}, \mathbf{v}_{j,f_i} \rangle x_i x_j
\]
where:
- \(\hat{y}(\mathbf{x})\) is the predicted target variable.
- \(w_0\) is the global bias.
- \(w_i\) are the weights of the model.
- \(\mathbf{x}\) is the feature vector.
- \(\mathbf{v}_{i,f_j}\) and \(\mathbf{v}_{j,f_i}\) are latent vectors that capture interactions between the \(i\)th feature and the field of the \(j\)th feature, and vice versa.
- \(\langle \mathbf{v}_{i,f_j}, \mathbf{v}_{j,f_i} \rangle\) is the dot product of these latent vectors.
- \(f_i\) and \(f_j\) are the fields of the \(i\)th and \(j\)th features respectively.
The main advantage of FFMs over standard FMs is that they can model higher-order feature interactions and capture more complex patterns in the data. This makes them particularly effective for tasks like CTR prediction, where interactions between high-level categories can be very informative.
The model parameters {i.e., the weights and latent vectors} can be learned using any standard optimization algorithm, such as stochastic gradient descent or alternating least squares.
The paper demonstrates the effectiveness of FFMs through a series of experiments on real-world datasets, showing that FFMs outperform other state-of-the-art methods in terms of prediction accuracy.
The implications of this work are significant for the field of recommendation systems and more generally for any problem involving high-dimensional categorical data. By providing a flexible and efficient way to model field-aware feature interactions, FFMs offer a powerful tool for predictive modeling in these settings.
go to post
Wide & Deep Learning for Recommender Systems
## TLDR
While the paper describes this approach as a combination of a deep neural network and a linear regression, it can also just be seen as a simple deep neural network, seeing as the formula for a single neuron is the same as a formula for a linear regression, just with an optional {e.g. RELU} non-linearity applied. Of course, linear regression fitting is much faster than using gradient descent, which is useful. Anyways, the approach is basically to have a logistic function {softmax neuron} that takes as input both a linear regression of your features {the 'wide' part of the model}, and a deep neural network's feature output {the 'deep' part of the model}.
## Summary
This paper introduces the Wide & Deep learning model, a novel architecture designed to achieve both memorization and generalization in the context of recommender systems. The model is a hybrid of a linear model and a deep neural network, which are trained jointly to make predictions.
The "wide" part of the model refers to the linear model, which is designed to have a large number of sparse input features. This wide model component is capable of memorization, or learning the frequent co-occurrence of items or features. This can be particularly useful for recommender systems, where certain item pairs or feature combinations may be highly predictive of user behavior.
The "deep" part of the model refers to the deep neural network, which has multiple hidden layers of dense embeddings. This deep model component is capable of generalization, or learning abstract feature interactions. This can help capture user preferences based on less obvious patterns in the data, leading to more diverse and personalized recommendations.
The architecture of the Wide & Deep learning model can be represented as follows:
\[
\hat{y} = \sigma(w_0 + \mathbf{w}^T \mathbf{x} + \mathbf{w}_d^T \mathbf{a}(\mathbf{x}))
\]
where:
- \(\hat{y}\) is the predicted target variable.
- \(\sigma\) is the logistic function, which squashes the output between 0 and 1.
- \(w_0\) is the global bias.
- \(\mathbf{w}\) is the weight vector for the wide model.
- \(\mathbf{x}\) is the input feature vector.
- \(\mathbf{w}_d\) is the weight vector for the deep model.
- \(\mathbf{a}(\mathbf{x})\) is the output of the last hidden layer of the deep model, which is a function of the input feature vector.
The model is trained to minimize a regularized logistic loss function, which can be optimized using gradient-based methods.
The authors also discuss practical considerations for implementing and training the Wide & Deep model, such as the use of feature engineering to create cross-product feature transformations for the wide model, and the use of embeddings to represent categorical features in the deep model. They demonstrate the effectiveness of the model through a series of experiments on the Google Play app recommendation system, showing that the Wide & Deep model significantly improves app recommendation quality compared to a deep-only model.
The implications of this work are significant for the field of recommendation systems. The Wide & Deep learning model provides a flexible and powerful framework for building recommender systems that can both exploit known user-item interactions and explore new and unexpected recommendations. This can lead to improved user satisfaction and engagement, making the Wide & Deep model a valuable tool for many real-world applications.
go to post
Neural Collaborative Filtering
## TLDR
Basically, tossed out the old approach of using matrix factorization {basically linear regressions w/ feature-interactions} and just used neural networks to model all this stuff. The paper describes the architecture as two parts: the Generalized Matrix Factorization {GMF} and the Multi-Layer Perceptron {MLP} parts. But from my point of view, at least when reading from a modern context these descriptions are a little overly complicated. Basically the GMF is just learned embedding matrices, and the MLP part is just feed-forward layers.
To simplify, I think you could think of Generalized Matrix Factorization {GMF} as an embedding layer. In the context of the Neural Collaborative Filtering {NCF} framework, GMF learns separate embeddings for users and items, and computes the element-wise product of these embeddings to represent user-item interactions. That being said, usually embedding layers are fed into later layers of the model, but in this case, it was fed directly into the final prediction softmax neuron. Which, I'm guessing, probably isn't ideal when you have sufficient data.
## Summary
The paper "Neural Collaborative Filtering" by He et al. presents a deep learning approach to collaborative filtering, a popular method used in recommender systems. Collaborative filtering often relies on matrix factorization techniques, which can be limiting in their ability to capture complex user-item interactions. This paper introduces a framework called Neural Collaborative Filtering (NCF), which leverages the power of neural networks to model these interactions more effectively.
The key idea behind NCF is to replace the inner product used in traditional matrix factorization with a multi-layer perceptron {MLP}, which can learn an arbitrary function from data. The MLP is used to learn the user-item interaction function.
The NCF framework consists of two models: Generalized Matrix Factorization {GMF} and Multi-Layer Perceptron {MLP}. GMF is a generalization of matrix factorization that replaces the inner product with an element-wise product followed by a linear layer. MLP uses multiple layers of non-linear functions to learn the user-item interaction function.
The proposed architecture is as follows:
\[
\hat{y}_{ui} = \sigma(a_{out}^T(h_u \circ h_i + b_{out})),
\]
where:
- \(\hat{y}_{ui}\) is the predicted rating of user \(u\) for item \(i\).
- \(\sigma\) is the sigmoid function, which maps the output to the range 0,1.
- \(a_{out}\) is the output layer weight vector.
- \(h_u\) and \(h_i\) are the latent vectors of user \(u\) and item \(i\), respectively.
- \(\circ\) denotes the element-wise product of the latent vectors.
- \(b_{out}\) is the output layer bias.
In addition, the authors propose a fused model called NeuMF, which combines GMF and MLP to better capture the linearity of GMF and non-linearity of MLP. The output layer of the NeuMF model is a weighted sum of the outputs from the GMF and MLP layers.
The authors evaluate the proposed NCF framework on several benchmark datasets and show that it outperforms a number of state-of-the-art methods, demonstrating the effectiveness of applying neural networks to collaborative filtering.
The implications of this work are significant for the field of recommender systems. The NCF framework provides a flexible and powerful tool for modeling user-item interactions, potentially leading to more accurate and personalized recommendations. It also opens up new opportunities for incorporating other types of information, such as textual or visual content, into the recommendation process.
go to post
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
## TLDR
Honestly this approach is very similar to the [Wide & Deep Learning for Recommender Systems
](https://noisedive.org/post/47) paper - basically, combining 'factorization machines' {linear models w/ feature interactions, lol} with some deep neural network layers to model more complex feature interactions. Looks like a slight difference is that DeepFM shares the feature embeddings between the FM and DNN components, which allows for a certain degree of interaction between low-order and high-order feature interactions. So basically, a learned embedding matrix was just inserted between the features and the linear regression and standard DNN components. Really seems like just a basic architecture change. Honestly, people just love to name things.
## Summary
The paper "DeepFM: A Factorization-Machine based Neural Network for CTR Prediction" presents a model named DeepFM, which is designed for click-through rate {CTR} prediction tasks. DeepFM is a hybrid model that combines the strengths of Factorization Machines {FMs} for explicit high-order feature interactions and Deep Neural Networks {DNNs} for implicit high-order feature interactions.
In recommendation systems and other CTR prediction tasks, modeling feature interactions is critical. Linear models and FMs are good at capturing low-order feature interactions, but they can struggle with high-order feature interactions. DNNs, on the other hand, can capture high-order feature interactions but do so implicitly.
DeepFM addresses this issue by integrating an FM component and a DNN component into a unified model, trained end-to-end. The FM component is used to model the low-order feature interactions, and the DNN component is used to model the high-order feature interactions.
The architecture of the DeepFM model can be represented as follows:
\[
\hat{y} = \sigma\left(y_{FM} + y_{DNN}\right),
\]
where:
- \(\hat{y}\) is the predicted target variable.
- \(\sigma\) is the sigmoid function, which maps the output to the range [0, 1].
- \(y_{FM}\) is the output of the FM component, which models the second-order feature interactions.
- \(y_{DNN}\) is the output of the DNN component, which models the high-order feature interactions.
- the features being used here in this formula aren't the raw features, but the output features from a learned embedding.
The key innovation of DeepFM is that it shares the feature embeddings between the FM and DNN components, which allows for a certain degree of interaction between low-order and high-order feature interactions.
The authors evaluate the proposed DeepFM model on several real-world CTR prediction datasets and show that it outperforms several state-of-the-art models, demonstrating the effectiveness of combining explicit and implicit feature interaction modeling in a unified model.
The implications of this work are significant for the field of CTR prediction and recommender systems. The DeepFM model provides a flexible and powerful tool for modeling both low-order and high-order feature interactions, potentially leading to more accurate and personalized recommendations. It also opens up new opportunities for incorporating other types of information, such as textual or visual content, into the recommendation process.
go to post
Neural Graph Collaborative Filtering
## TLDR
Basically, learned user and item embeddings are learned, based on a user-item interaction graph is represented as an adjacency matrix \(A\), where the element \(A_{ij}\) is 1 if user \(i\) interacted with item \(j\), and 0 otherwise. You end up with an embedding matrix: $(N_{users} + N_{items}) X N_{embedding dimensions}$ {could be thought of as two separate ones, for clarity}. Then the dot-product of your given user and item is taken during prediction to predict interactions.
Basically, because your output embedding dimension is much smaller than the number of items or the number of users {generally}, the model can't afford to just memorize interactions. As a result, during training users and items are implicitly clustered, so that - for example, baby products all produce similar embedding scores, because a user who buys baby products is likely to have interacted with other baby products. Similarly, such a user would get an embedding that represents 'person who tends to buy baby products', among other things.
Personally, I'm not really sure I understand why this is called a 'Graph Neural Network'. I mean, it sounds fancy, and that's nice. But what's the difference between it and just a neural network with a learned embedding for input users and items? I literally can't tell, if I'm missing something obvious, tweet me at @hillarymsanders.
## Model Architecture
The architecture of the proposed NGCF model is formed by aggregating embeddings propagated in the user-item interaction graph. The authors use a graph neural network {GNN} to capture the collaborative filtering {CF} signals from the graph structure of the user-item interactions.
The user-item interaction graph is represented as an adjacency matrix \(A\), where the element \(A_{ij}\) is 1 if user \(i\) interacted with item \(j\), and 0 otherwise. The graph is undirected and self-connected, meaning it has self-loop edges.
Given the adjacency matrix \(A\), the initial embedding of user \(i\) or item \(i\) is represented as \(e_i^0\), and the model iteratively updates the embedding based on the adjacency of nodes in the graph. The updating rule for each iteration \(l\) can be described as:
\[
e_i^{(l+1)} = LeakyReLU \left( \sum_{j \in \mathcal{N}_i} \frac{1}{\sqrt{|\mathcal{N}_i||\mathcal{N}_j|}} (W_1 e_j^{(l)} + W_2 (e_j^{(l)} \odot e_i^{(l)})) \right)
\]
where \(e_i^{(l+1)}\) is the updated embedding of node \(i\) at the \(l+1\) iteration, \(\mathcal{N}_i\) denotes the first-order neighbors of node \(i\), \(W_1\) and \(W_2\) are learnable weight matrices, and \(\odot\) denotes element-wise multiplication. The normalized factor \(\frac{1}{\sqrt{|\mathcal{N}_i||\mathcal{N}_j|}}\) is used to avoid the scale of updates growing with the number of neighbors.
## Training
The model is trained by optimizing a pairwise BPR {Bayesian Personalized Ranking} loss, which is a widely used loss function for implicit feedback recommendation. Given a triplet \((u, i, j)\) where user \(u\) interacted with item \(i\) but not with item \(j\), the BPR loss is defined as:
\[
-\sum_{(u,i,j) \in \mathcal{D}} \log \sigma(e_u^{(K)} \cdot e_i^{(K)} - e_u^{(K)} \cdot e_j^{(K)})
\]
where \(\mathcal{D}\) denotes the training set, \(e_u^{(K)}\), \(e_i^{(K)}\), and \(e_j^{(K)}\) are the final embeddings of user \(u\) and items \(i\) and \(j\) after \(K\) iterations, and \(\sigma\) is the sigmoid function.
## Implications
The NGCF model has several significant implications:
1. **Modeling High-order Connectivities**: The model captures high-order connectivities in the interaction graph. This is in contrast to traditional CF methods that mainly capture first-order connectivities {i.e., direct interactions}. By modeling high-order connectivities, the model can potentially discover more intricate and latent patterns in user
-item interactions, leading to better recommendation performance.
2. **Learning on Graph Structure**: By leveraging GNNs, the model learns embeddings of users and items based directly on the graph structure of the user-item interaction graph. This is a departure from conventional matrix factorization-based CF methods, which learn from the user-item interaction matrix. This approach allows the model to better preserve the topological properties of the interaction graph and can lead to more accurate recommendations.
3. **Applicability to Implicit Feedback**: The model is designed for and tested on datasets with implicit feedback, such as click data. Implicit feedback is more abundant and easier to collect than explicit feedback {like ratings}, but it is also noisier and more challenging to model. The success of NGCF on such datasets indicates its effectiveness in handling implicit feedback.
4. **Scalability**: NGCF is a scalable model, as it only needs to compute embeddings for the nodes in the graph, which correspond to the users and items. It doesn't need to compute a separate embedding for each user-item pair, which makes it more scalable for large-scale recommendation tasks.
In summary, "Neural Graph Collaborative Filtering" {NGCF} by Xiang Wang et al. represents a significant advance in the field of recommendation systems. It proposes a novel approach that leverages the strengths of Graph Neural Networks {GNNs} to capture high-order connectivities in the user-item interaction graph and provide more accurate recommendations, especially in the context of implicit feedback. The research opens up new avenues for the integration of GNNs in building more effective and scalable recommendation systems.
go to post
Self-Attentive Sequential Recommendation
## TLDR
SASR stands for "Self-Attentive Sequential Recommendation". This approach focuses on sequence-aware recommendations {e.g. something a company like Tik-Tok might use, or any website that wants to be able to shift recommendations rapidly}.
My interpretation of the approach is this:
- train learned embeddings to transform an item or user into a learned embedding vector
- instead of just taking the dot product of a user and item to see if that user is likely to interact with that item, this approach uses transformers at attention to process a user and various {recent} items that user has interacted with *as a sequence*.
- Then like a standard transformer-based language model, the model outputs its guess of the next most likely item a user will interact with {or rather, a probability distribution over all items}.
*NOTE*: As with most recommendation approaches, all of this is tricky because of the self-fulfilling prophecy issue: if you recommend an item to a user, they're more likely to click on it, and if you have multiple ways of recommending items to users at once with varying powers {think Netflix}, this becomes very muddled. But you can still learn valuable signal from just this $P(interacted | was served)$ estimate. In practice, you can help deal with this by serving random content sometimes (or content with high temperature, basically) to aid in figuring out better probabilities, but it will always be a bit of a tricky issue.
## Overview
The "Self-Attentive Sequential Recommendation" paper introduces a novel method for recommendation systems, particularly sequence-aware recommendations. The authors propose a model called SASRec, an acronym for Self-Attentive Sequential Recommendation. This model is a transformer-based architecture that leverages self-attention mechanisms to capture the sequential behavior of users' actions over time.
## Architecture and Model
The model is fully attentive and does not rely on any recurrent or convolutional architecture. It takes sequences of items as inputs and employs self-attention to capture dependencies between items in the sequence. The model uses a stacked, transformer-based architecture with positional encoding to handle the sequential nature of the data.
Specifically, the model consists of an embedding layer, multiple self-attention layers, and a final prediction layer. In the embedding layer, each item in the sequence is embedded into a dense vector. The self-attention layers then capture dependencies between these items, and the prediction layer produces the next item in the sequence.
The self-attention mechanism is particularly important as it allows the model to assign different weights to different items in the sequence based on their relevance to the current prediction. In particular, the self-attention mechanism in this model employs multi-head attention, which enables the model to focus on different parts of the sequence at the same time.
The attention weight of item \(j\) for item \(i\) is computed as follows:
\[
A_{ij} = \frac{\exp{\text{{score}}(E_i, E_j)}}{\sum_{k=1}^{n} \exp{\text{{score}}(E_i, E_k)}}
\]
where \(E_i\) and \(E_j\) are the embeddings of item \(i\) and \(j\), and score is a function that calculates the relevance of \(E_j\) to \(E_i\). In the case of the transformer model, the score function is a scaled dot product:
\[
\text{{score}}(E_i, E_j) = \frac{E_i \cdot E_j}{\sqrt{d}}
\]
where \(d\) is the dimension of the embeddings.
## Training
For training the model, the authors propose using the BPR {Bayesian Personalized Ranking} loss, a pairwise ranking loss. Given a triplet of user, positive item, and negative item \(u, i, j\), the BPR loss is defined as follows:
\[
\text{{BPR}}(u, i, j) = -\ln \sigma(\hat{y}_{ui} - \hat{y}_{uj})
\]
where \(\hat{y}_{ui}\) and \(\hat{y}_{uj}\) are the model's predictions for the positive and negative items, and \(\sigma\) is the sigmoid function.
## Implications
The proposed SASRec model represents a significant shift in the paradigm of recommendation systems. By moving away from RNNs and CNNs, which have dominated this field, the model opens up new possibilities for leveraging the power of self-attention in sequence-aware recommendations.
Furthermore, the model's full attention mechanism allows it to capture long-range dependencies in the data, which can be critical for making accurate recommendations. This could have significant implications in areas like e-commerce, where understanding a user's entire interaction history can lead to more personalized and accurate recommendations.
go to post
Deep & Cross Network {DCN}
## TLDR
Basically just an architecture change from a basic feed-forward neural network in the contect of recommendation engines. The architecture consists of some more deep, small layers, plus these 'cross-networks', which basically multiply an earlier layer's output {or original feature} with the current layer's output dot product, the latter acting as a sort of feature-importance signal. {Somewhat similar idea to a skip connection, but different due to the multiplying}.
Seems like mostly just a fairly simple architectural change that worked well for the problem at hand. But if I had to bet money {well, if I had to bet money without looking up the actual comparisons, if there are any}, I'd bet that the transformer-based approaches perform better than this {and handle sequence-based data much better}. This approach did better on the tested datasets compared to some basic approaches {FFN, logistic gradient-boosted decision tree, convolutional neural network, wide & deep, and product-based neural networks)., but that's not saying *much*.
## Summary
Sure, I understand. Here's the modified version of the text:
The Deep & Cross Network {DCN} was introduced by Ruoxi Wang et al. in 2017 for ad click predictions. The core idea was to effectively model feature interactions in high-dimensional sparse data, which is often seen in online advertising.
The authors argue that traditional deep learning approaches, such as Feedforward Neural Networks {FNN}, can model feature interactions but fail to do so explicitly and efficiently. They argue that FNNs suffer from low-degree polynomial and high computational complexity. Their solution, the DCN, is designed to explicitly and efficiently capture bounded-degree feature interactions in an automatic fashion.
The DCN combines a 'deep network' {DNN} component and a 'cross network' component to leverage both low- and high-order feature interactions. The cross network is responsible for explicit, high-order feature crossing, and the deep network is responsible for implicit, low-order feature crossing.
The architecture of DCN can be visualized as follows:
```
Input
|
Embedding
|
Cross Network --------> Stacking
| |
Deep Network -------------
|
Output
```
**Cross Network**:
The cross network applies explicit feature crossing. It takes the input features and applies multiple layers of feature crossing, which can be mathematically represented as:
\[
x_{l+1} = x_0 \times (x_l \cdot w_l + b_l) + x_l
\]
where \(x_l\) is the \(l^{th}\) layer's output, \(x_0\) is the original input vector, \(w_l\) and \(b_l\) are the layer's weight and bias, and \(\times\) and \(\cdot\) denote element-wise product and dot product, respectively. The dot product \(x_l \cdot w_l\) can be seen as generating a feature importance vector.
**Deep Network**:
The deep network is a standard feedforward neural network {FNN}, which implicitly learns feature interactions. The architecture and layer number can be customized based on the application scenario.
**Stacking**:
The outputs of the cross network and the deep network are stacked together {concatenated} to form the final output. The final output layer is a sigmoid function for binary classification {click or not click}.
The authors empirically demonstrate that the DCN model outperforms traditional models such as LR {Logistic Regression}, GBDT {Gradient Boosting Decision Tree}, and FNN {Feedforward Neural Network} on a large-scale ad click dataset. The DCN model is also argued to be more efficient in terms of computational complexity and memory usage.
In terms of implications, this paper provides a significant step forward in handling high-dimensional sparse data, which is common in many online applications beyond ad click prediction. The proposed DCN model can efficiently and effectively capture both low- and high-order feature interactions in an automatic fashion, without the need for manual feature engineering. This can greatly simplify the process of building models for such data, making it easier to apply deep learning techniques in these domains.
The approach is quite versatile and flexible, which means it could be applied in many other fields beyond advertising, such as recommendation systems, search engines, social networking, and any other area where high-dimensional sparse data is common.
go to post
Deep Interest Network {DIN}
## TLDR
More or less, they use attention to learn the relevance of an ad to a user's past behaviors.
## Summary
The Deep Interest Network (DIN) is a model developed by researchers at Alibaba. It was designed to address challenges in click-through rate (CTR) prediction, which is a key problem in online advertising systems. The main contributions and components of the DIN can be summarized as follows:
**1. User Interest Modeling:**
The authors propose a novel way to model user interest by considering the user's historical behaviors. Traditional models, such as the Wide & Deep model, treat user behavior features independently, which doesn't capture diverse interests of users. DIN, on the other hand, designs an interest extractor layer to adaptively learn the representation of user interests from historical behaviors with respect to a certain ad.
**2. Adaptive Activation Function:**
The authors introduce an activation function to model the diverse contributions of user interests to the prediction of different ads. This function is essentially an attention mechanism that provides a weight to each user's historical behavior according to its relevance to the candidate ad. The formula of the activation function is:
\[
a(\mathbf{v}, \mathbf{t}) = \frac{\exp(\mathbf{v}^T\mathbf{t})}{\sum_{\mathbf{v'} \in \mathbf{V}} \exp(\mathbf{v'}^T\mathbf{t})}
\]
where \(\mathbf{v}\) is a user's historical behavior embedding, \(\mathbf{t}\) is the target ad embedding, and \(\mathbf{V}\) is the set of all user behavior embeddings.
**3. Architecture:**
The DIN model consists of an Embedding & Combination layer, an Interest Extractor layer, and a Stacking layer.
- The Embedding & Combination layer is responsible for transforming the categorical input features into low-dimensional dense embeddings, and combining them with numerical input features.
- The Interest Extractor layer uses the activation function to weigh user behavior embeddings, then sum them up to get the user's interest representation.
- The Stacking layer is a traditional feed-forward neural network, which takes the combined features from the first layer and user interest representation from the second layer to make the final prediction.
**4. Experimental Results:**
The authors reported that DIN significantly outperformed traditional models on a large-scale dataset from the Alibaba display advertising system.
Implications of the paper are profound in the field of online advertising. The DIN model's novel approach to capturing user interest and using attention mechanisms to weigh these interests is a significant contribution to the field of CTR prediction. This approach allows for more personalized and accurate ad recommendations, potentially leading to increased user engagement and revenue for online advertising platforms.
go to post